操作系统大题解析
进程同步问题
基础知识
首先需要知道的是,进程同步问题大多都是从信号量机制出发,考查对一段程序进行PV操作
在阅读题目时,一定要想信号量机制的应用,找出并标记出来
如同典型例题一样,PV问题分为3种:
生产者–消费者问题
步骤如下:
- 确定有几类进程,每个进程对应一个函数
- 在函数内部,用中文描述动作(注意是只做一次or不断重复)
- 在做动作之前,是否需要进行P操作,如果要进行P操作,则同时把V操作也添加上去
- 所有的PV操作写完后,再去定义信号量
- 检查多个P操作是否会导致死锁
一般来说,就是注意缓冲区的容量的信号量empty,和相关产品的信号量
哲学家进餐问题
哲学家进餐问题有多种思路,最简单的思路就是:直接一次性拿走所有资源,然后判断是否满足条件,如果满足,则解锁,跳出while循环,如果不满足,则解锁,再进行while循环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| Semophore Lock=1;
int a,b,c=XX;
Process(){
while(1){
P(lock);
if(所有资源都够){
所有资源int值减少
取XXX资源
V(lock);
break;
}
V(lock)
}
做进程该做的事(哲学家进餐)
P(lock);
归还所用资源,所有资源int值增加
V(lock);
}
|
读者–写者问题
特点是实现同类进程不互斥,异类进程互斥
实现方法是:第一个用之前负责上锁,最后一个用完之后负责解锁
408

此题很明显的看可以初看,很像是生产者–消费者的变形,区别只是在于生产者生成的东西,只能给部分消费者使用
所以根据生成的数字,通知相应的进程即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
semaphore mutex=1;
semaphore odd=0,even=0;
sempahore empty=N
cobegin{
while(true){
x=produce();
P(empty);
P(mutex);
Put();
V(mutex);
if(x%2==0)
V(even);
else
V(odd);
}
Process P2()
while(True){
P(odd);
P(mutex);
getodd();
V(mutex);
V(empty);
countodd();
}
Process P3()
while(True){
P(even);
P(mutex);
geteven();
V(mutex);
V(empty);
countodd();
}
}
|

仅有一个进程,自然就没有进程之间的同步问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
cobegin
参观者进程i{
P(num);
P(mutex);
进门
V(mutex);
参观
P(mutex);
出门
V(mutex);
V(num);
|

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
cobegin(){
Process 顾客
{
P(seat);
P(mutex);
取号
V(mutex);
V(cos);
P(servive);
接受服务
}
Process 营业员
{
while(True){
P(cos);
V(seat);
叫号
V(service);
}
}
}coend
|

在原来的消费者生产者问题上,新加了一个限制条件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
producer()[
while(1){
produce();
P(empty);
P(mutex2);
input;
V(mutex2);
V(product);
}
comsumer(){
while(1){
P(mutex1)
for(int i=0;i<10;i++){
P(product);
P(mutex2);
output;
V(mutex2);
V(empty);
consumer;
}
V(mutex1);
}
}
|

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
A{
while(True){
P(fullA);
p(mutex1);
从A的信箱中取出一个邮件
V(mutex1);
V(emptyA);
回答问题并提出一个新问题
P(emptyB);
p(mutex2);
将新邮件放入B的信箱
V(mutex2);
V(fullB);
}
}
B{
while(True){
P(fullB);
p(mutex2);
从B的信箱中取出一个邮件
V(mutex2);
V(emptyB);
回答问题并提出一个新问题
P(emptyA);
p(mutex1);
将新邮件放入B的信箱
V(mutex1);
V(fullA);
}
}
|

这种程序题首先要搞清楚的就是,修改变量的互斥关系
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
thread1{
cnum w;
P(mutex1);
w=add(x,y);
V(mutex1);
}
thread2{
cnum w;
P(mutex2);
P(mutex3);
w=add(y,z);
V(mutex3);
V(mutex2);
}
thread3{
cnum w;
w.a=1;
w.b=1;
P(mutex3);
z=add(z,w);
V(mutex3);
P(mutex1);
P(mutex2);
y=add(y,w);
V(mutex1);
V(mutex2);
}
|

哲学家问题的变种,解决问题的思路之一就是限制进餐的哲学家人数,从n人变为n-1人
- 如果m<n,那么碗(n)的数量就限制了可同时吃饭人的数量
- 如果m>n,那么碗(n)至少要是人数-1,即n=m-1才能发挥作用
所以将碗的数量定义为min(n-1,m)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
for(int i=0;i<n;i++)
chopsticks[i]=1;
bowl=min(n-1,m);
CoBegin
while(true){
think;
P(bowl);
P(chopsticks[i]);
P(chopsticks[(i+1)%n]);
就餐;
V(chopsticks[i]);
V(chopsticks[(i+1)%n]);
V(bowl);
}
CoEnd
|

PV操作可以控制操作的前后顺序:如果想要A操作在C之前,那么就在C之前加一个P操作,而在A操作之后加一个V操作,这样,C就必要在A之后了
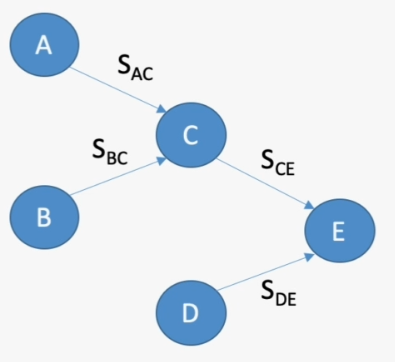
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| Semaphore AC=0;
Semaphore BC=0;
Semaphore CE=0;
Semaphore DE=0;
A(){
进行A操作
V(AC);
}
B(){
进行B操作
V(BC);
}
C(){
P(AC);
P(BC);
进行c操作
V(CE);
}
D(){
进行D操作
V(DE);
}
E(){
P(CE);
P(DE);
进行E操作
}
|
874

显示是生产者和消费者问题的变形,框中是缓冲区,而球是产品
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| Semaphore wb=0;
Semaphore bb=0;
Semaphore empty=2;
Semaphore mutex=1;
男教师{
while(1){
P(empty);
P(mutex);
放白球
V(mutex);
V(wb);
}
}
女教师{
while(1){
P(empty);
P(mutex);
放黑球
V(mutex);
V(bb);
}
}
男学生{
while(1){
P(wb);
P(mutex);
拿白球
V(mutex);
V(empty);
}
}
女学生{
while(1){
P(bb);
P(mutex);
拿黑球
V(mutex);
V(empty);
}
}
|

和上一道题几乎一样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| Semaphore empty=1
Semaphore mutex=1
Semaphore chao=0
Semaphore rice=0
炒饭师傅{
while(1){
P(empty);
P(mutex);
做炒饭
V(mutex);
V(chao);
}
}
炒面师傅{
while(1){
P(empty);
P(mutex);
做炒饭
V(mutex);
V(rice);
}
}
炒饭学生{
while(1){
P(chao);
P(mutex);
拿炒饭
V(mutex);
V(empty);
}
}
炒面学生{
while(1){
P(rice);
P(mutex);
拿炒面
V(mutex);
V(empty);
}
}
|
进程调度问题

解析:
- 由于采用了静态优先数,当就绪队列中总有优先数较小的进程时,优先数较大的进程一
直没有机会运行,因而会出现饥饿现象
- 优先数
priority的计算公式为:priority=nice+k1×cpuTime-k2×waitTime,其中k1>0,k2>0,用来分别调整cpuTime和waitTime在priority中所占的比例。waitTime可使长时间等待的进程优先数减小,从而避免出现饥饿现象。
页面转换问题
基础知识
页面转换问题是常考问题,重点有两个,分别是二级页表和地址转换的过程
二级页表如下:
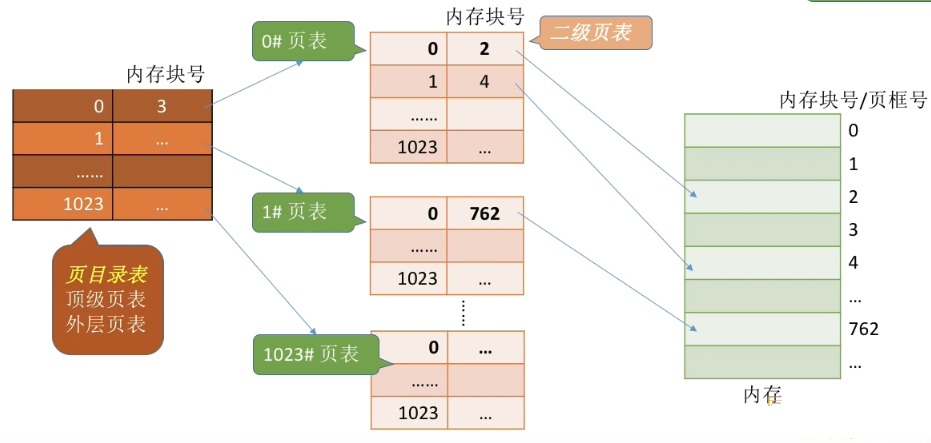

其中有如下概念需要说明:
一般题目会给出,二级页表的结构以及页表项,页目录项的大小,注意计算机系统是否用字节编址
一级页号又称页目录号,二级页号又称页号/页表索引,页内偏移量又称页内地址
页表项:在页表中,一个页号与其对应的物理块号称之为一个页表项
页目录项:在页目录表中,一个页号与其对应的二级页号号称之为一个页目录项
页目录表的起始物理地址:寄存在寄存器orPCB中
系统的位数$\Leftrightarrow$虚拟地址空间大小$\Leftrightarrow$虚拟地址的总位数$\Leftrightarrow$一级页号+二级页号+页内偏移量的位数
页内偏移量$\Leftrightarrow$页面大小$\Leftrightarrow$页框大小
有关页目录号(一级页号)的总结:
逻辑页号$\Longleftarrow$页目录号+页号
页目录表的大小$\Longleftarrow$页目录号/页目录项的大小
页目录项的物理地址$\Longleftarrow$页目录表的起始地址+页目录号×页目录项的大小
页表的起始物理地址$\Longleftarrow$页目录项的具体内容(即下一级页表存放的页框号)
有关页号(二级页号)的总结:
二级页表的大小$\Longleftarrow$页号/页表项的大小
页表项的物理地址$\Longleftarrow$页表的起始物理地址(页框号)+页表项长度×页号
页表项的具体内容(物理地址存放的页框号)$\Longleftarrow$页表项的物理地址
物理地址$\Longleftarrow$页框号+页内偏移量
注意区别物理地址和逻辑地址和页表项的物理地址
物理地址的前x位表示页框号,后x位表示页内偏移量
逻辑地址的前x位表示页号,后x位表示页内偏移量
页表项的物理地址:页框号+页号×页表项大小
页目录项的物理地址:页目录表的起始地址+页目录号×页目录项的大小
最为复杂的是求二级页面中页表项的物理地址
需要的条件有:
- 页目录项中对应此页表项的物理块中,所存放的页框号
- 该页表项在页表中页号
- 页表项的大小
最终结果为页框号+页号×页表项大小
带快表的一级页表的请求分页管理方式
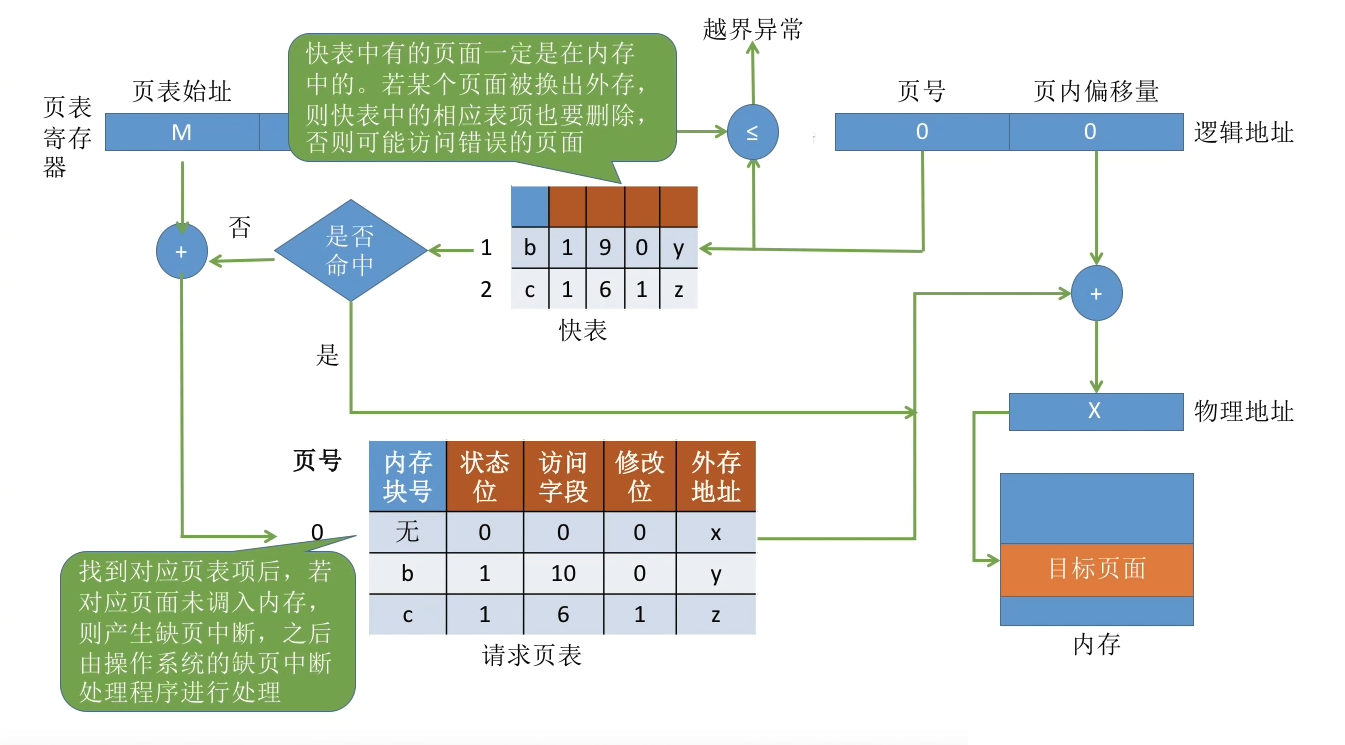
访存时会优先查找快表,然后再查慢表,当发生缺页时,需要页面置换,同时更新快表和慢表,然后再重复流程,所以发生缺页到查找成功的时间为:
访问TLB(未命中)+访问慢表(未命中)+处理缺页+再次访问TLB(命中)+访问目标页面
CLOCK算法中页表的标志有:内存块号 状态位 访问字段 外存地址
改进型CLOCK算法中页表的标志有:内存块号 状态位 访问字段 修改位 外存地址
408
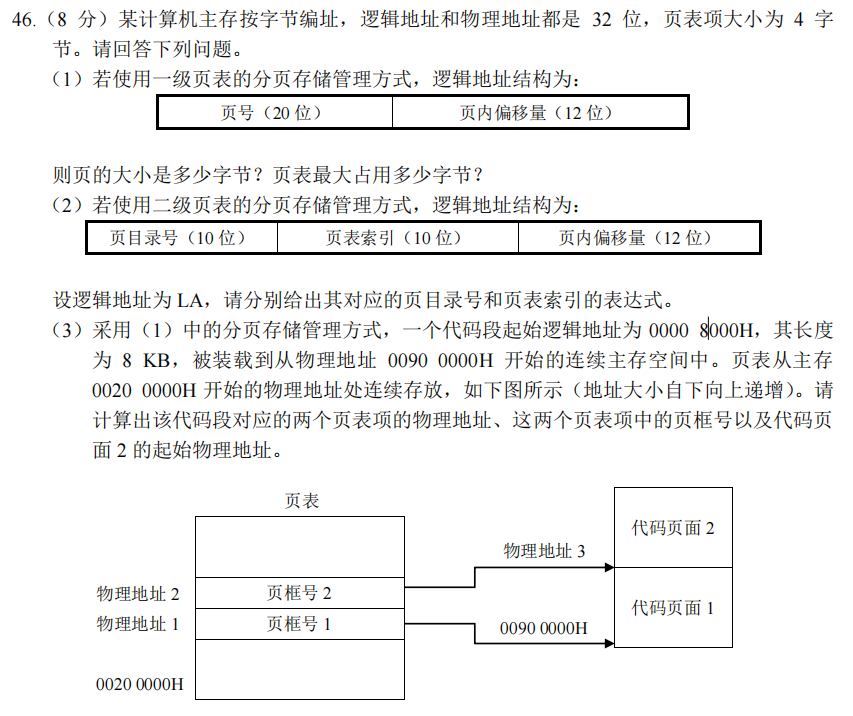
页框:将内存划分成一块块的格式,每个物理叫做页框
页面:按照内存中划分形式,将进程划分成一个个块,每个块叫页面
页内偏移量为12位,则页的大小是$2^{12}B$,即4KB,页表占用的页表项的个数为$2^{32}/2^{12}=2^{20}$,即1MB,占用的字节为1×4=4MB
页目录号就是逻辑地址的前10位,页表索引就是逻辑地址的中间10位
页目录号可以表示为(LA>>22),页表索引可以表示为(LA>>12)&0x3FF(0x3FF会自动补足0)
已知代码段的起始逻辑地址为0000 8000H,可知他们的页号是8,计算得到物理地址1为
0020 0000H+8×4=0020 0020H,物理地址2为0020 0024H
页框号是物理块号,即是00900H和00901H
物理地址3为00901000H
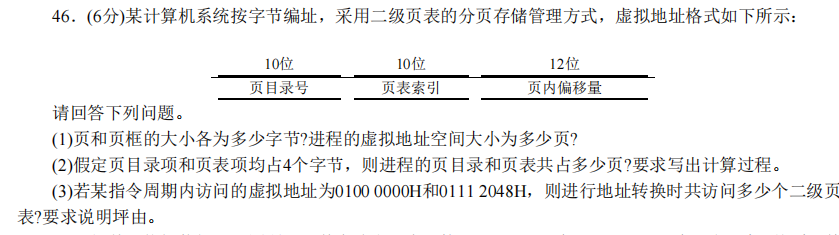
- 页的大小等于页框的大小,都为$2^{12}=4KB$,虚拟空间的大小为$2^{32}/2^{12}=2^{20}$页
- 页目录占$(2^{10}×4)/2^{12}=1$页,页表项占$(2^{20}×4)/2^{12}=1024$页,共占1024+1=1025页
- 访问的是同一个二级页表 页目录号010=0000 0001 00和 011=0000 0001 0001,前10位都相同
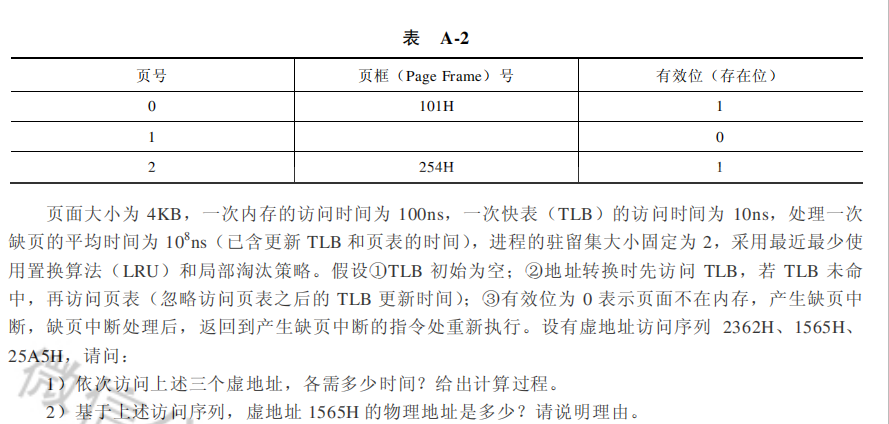
根据页式管理的工作原理,应先考虑页面大小,以便将页面和页内位移分解出来,页面大小为4KB,即是$2^{12}$,占据了虚地址的低12位,虚地址剩余的位置即是页号
2362的页号是2,快表中没有,两次访存,访问快表10ns+两次访问存时间为10+100+100=210ns
1565的页号是1,会产生缺页中断,时间为访问快表,访问内存,产生缺页中断并处理,访问快表,访问内存 总时间为10+100+$10^{8}$+10+100=100 000 220ns
25A5的页号是2,快表中已经记录有了,一次访存,时间为10+100=110ns
- 根据LRU的置换算法,会把0号页面淘汰,那么分配给1号页面的页框号为101H,则虚地址的1565H的565表示页内偏移量,物理地址为101565H

- 页框号为21 起始驻留集为空,而0页对应的页表为空闲链表中的第三个空闲页框,对应的页框号是21
- 页框号为32,在第三轮扫描中,第二轮被换下的32页框被重新放入,所以是32
- 页框号为41,第2页从来没有被访问过,从空闲页框链表中取出链表头的页框41
- 适合,如果程序的时间局部性越好,从空闲页框链中重新取回的机会越大,该策略优势也就越明显

逻辑地址空间占64KB,即是$2^{16}$,页的大小为1KB,则页偏移量占据后10位,17CAH=0001 0111 1100 1010 的前6位表示页号,页号为5
FIFO会将第0号页面淘汰,页框号为7,物理地址为0001 1111 1100 1010 即是1FCAH
Clock会将第2号页面淘汰,页框号为2,物理地址为0000 1011 1100 1010即是 0BCAH
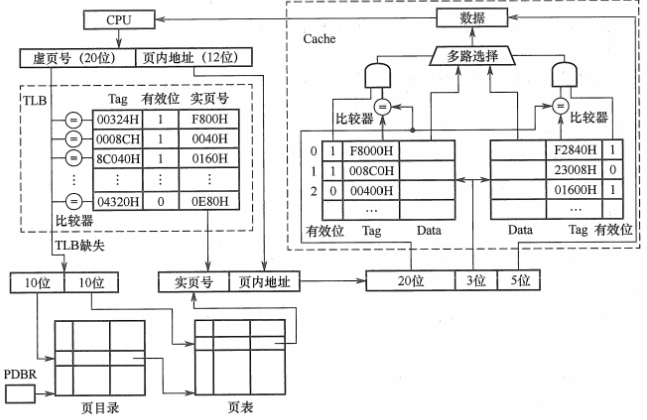

前10位是页目录的号数,中间10是页表号,最后12位是页内偏移量
0000 0001 1000 0000 0110 0000 0000 1000 0180 6008H
物理,会,不会
访问,修改

页面大小=2^12B=4KB,每个页面正好可以放下1024个数组元素,即一行,$a[1][2]$会存放在第2个页面,地址偏移量为2×4B=8B,虚拟地址为:页号+页内偏移量=10801 008H
10810 008H= 0001000010 0000000001 000000001000,前10位是042H,中间10位是001H,偏移量是008H
对应的页目录项的物理地址为 0020 1000H+4×42H=0020 1108H
若页框号为00301H,则对应的页表项的物理地址为:00301 000H+1×4H=00301 004H
数组a在虚拟地址空间必须连续存放,由于数组a不止占用1页,相邻逻辑页在物理上不一定相邻,可以不连续
按行遍历的局部性更好,因为数组的一行被保存在同一个页面
874

- 8GB=$2^{33}$,即虚拟地址空间有33位,其中页内偏移=页框大小=页面大小为8KB即$2^{13}$B,要占据13位,剩下的地址空间为46-13=33位,一个页框能有$2^{13}/4=2^{11}$个页表,所以应该设计为$33/11=3$级页表
- 在请求分页存储中,PTE应该包括内存块号,有效位,访问位,修改位,外存地址

此时的地址变换过程是:在 CPU给出有效地址后,由地址变换机构自动地将页号 P送入高速缓冲寄存器,并将此页号与高速缓存中的所有页号进行比较,若其中有与此相匹配的页号,便表示所要访问的页表项在快表中。于是,可直接从快表中读出该页所对应的物理块号,并送到物理地址寄存器中。如在快表中未找到对应的页表项,则还须再访问内存中的页表,找到后,把从页表项中读出的物理块号送往地址寄存器; 同时,再将此页表项存入快表的一个寄存器单元中,亦即,重新修改快表。
在请求分页存储中,PTE应该包括内存块号,有效位,访问位,修改位,外存地址
现对其中各字段说明如下;
- 状态位(存在位)P∶由于在请求分页系统中,只将应用程序的一部分调入内存,还有一部分仍在外存磁盘上,故须在页表中增加一个存在位字段。由于该字段仅有一位,故又称位字。它用于指示该页是否已调入内存,供程序访问时参考。
- 访问字段 A∶ 用于记录本页在一段时间内被访问的次数,或记录本页最近已有多长时间未被访问,提供给置换算法(程序)在选择换出页面时参考。
- 修改位 M∶ 标识该页在调入内存后是否被修改过。由于内存中的每一页都在外存上保留一份副本,因此,在置换该页时,若未被修改,就不需再将该页写回到外存上,以减少系统的开销和启动磁盘的次数;若已被修改,则必须将该页重写到外存上,以保证外存中所保留的副本始终是最新的。简而言之,M 位供置换页面时参考。
- 外存地址∶ 用于指出该页在外存上的地址,通常是物理块号,供调入该页时参考。

分页在储管理实现的基本思想:在分页存储管理中,将每个作业的逻辑地址空间分为大小相同的块,称为虚页面或页,通常页面大小为2的整数次幂(512K~4K)。同样地,将物理空间也划分为与页面大小相等的块,称之为存储块或页框,为作业分配存储空间时,总是以页框为单位。例如:一个作业的地址空间有M页,那么只要分配给它M个页框,每一页分别装入一个页框即可
为了确保每道程序都只在自己的内存区中运行,必须设置内存保护机制。一种比较简单的内存保护机制是设置两个界限寄存器,分别用于存放正在执行程序的上界和下界。在程序运行时,系统须对每条指令所要访问的地址进行检查,如果发生越界,便发出越界中断请求,以停止该程序的执行,即静态的界地址保护
而分页和分段采用的越界保护,需要根据界址寄存器储存起始地址,根据地址变换机构来判断是否越界
在内存中划出了一块共享存储区域,诸进程可通过对该共享区的读或写交换信息,实现通信,数据的形式和位置甚至访问控制都是由进程负责,而不是 OS。这种通信方式属于高级通信。需要通信的进程在通信前,先向系统申请获得共享存储区中的一个分区,并将其附加到自己的地址空间中,便可对其中的数据进行正常读、写,读写完成或不再需要时,将其归还给共享存储区。

64位虚拟地址空间,页面长4KB=$2^{12}$B,即占12位,剩下的64-12=52位,而一页能存储的页表项为4KB/4B=$2^{10}$,即占10位,所以至少需要6层分页策略才行

- $2^{48}/2^{12}$=$2^{36}$,则36位作为页表位数,$4KB/8B=2^{9}$,1级页表占9位,36/9=4,需要4级页表
- 0.98×(10+100)+0.02×(10+100+100)=112ns
- 0.98×(10+100)+0.02×(10+100+100+100)=114ns
- p×(10+100)+(1-p)×(10+100+100+100)<120ns p=95%
- 每段最大为$4GB=2^{32}$,则段内偏移量为32位,段号为16位,最多$2^{16}$段,多级页表的每级页表最多有9位,所以20/9=2.2<3,段内采取3级页表
文件存储问题
基础知识
分配方式有3种
- 连续分配
- 链接分配
- 索引分配
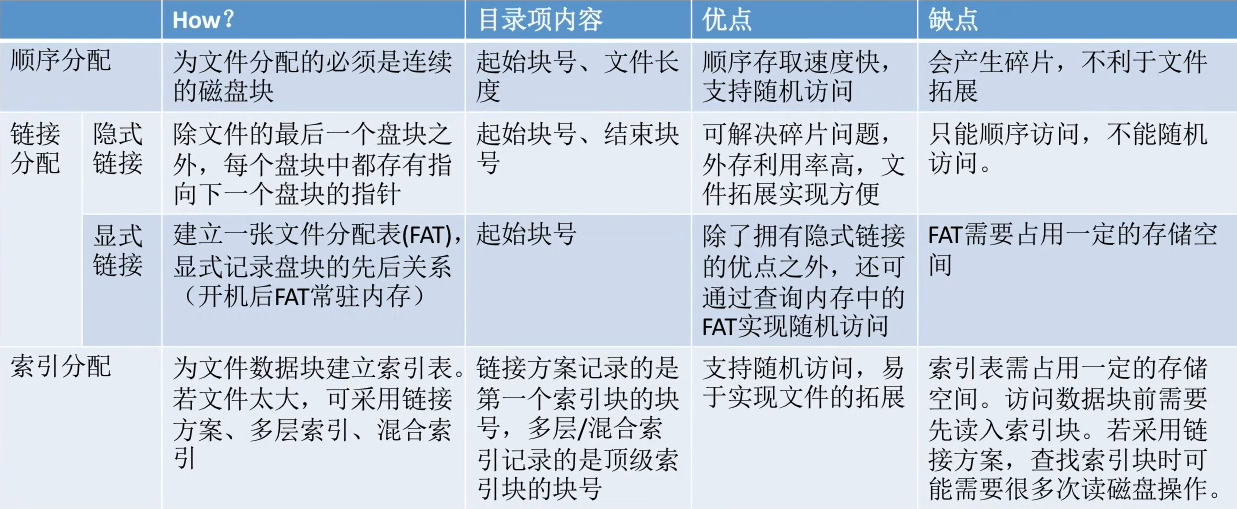
不同的分配方式会导致不同的结果,但精髓在于:如何存储器中块的数目?
显式链接:FAT的位数
隐式链接:链接指针的位数
直接索引:索引结点的位数
间接索引:每一个簇能存放索引结点的个数
计算如下:
链接分配
显式链接
常给出的概念:FAT表项大小 簇的大小
FAT表项位数$\Longleftarrow$FAT表项大小
FAT表项数目$\Longleftarrow$FAT表项位数
FAT的最大长度$\Longleftarrow$FAT表项大小×FAT表项数目
最大文件长度$\Longleftarrow$FAT的表项的数量×簇的大小
隐式链接:
常给出的概念:簇的大小 链接指针的大小or链接数据区的大小
磁盘块的位数$\Longleftarrow$链接指针的大小
磁盘块的数目$\Longleftarrow$磁盘块的位数
最大文件长度$\Longleftarrow$(块的大小-指针大小)×磁盘块的数目
直接索引
文件系统空间的最大容量 常给出
磁盘块的数量$\Longleftarrow$文件系统容量/磁盘簇的大小
索引表项的位数$\Longleftarrow$磁盘块的数量
索引表项的大小$\Longleftarrow$索引表项的位数
索引表项的数量$\Longleftarrow$索引表区的大小/索引表项的大小
文件最大长度$\Longleftarrow$索引表项的数量×磁盘块的大小
408
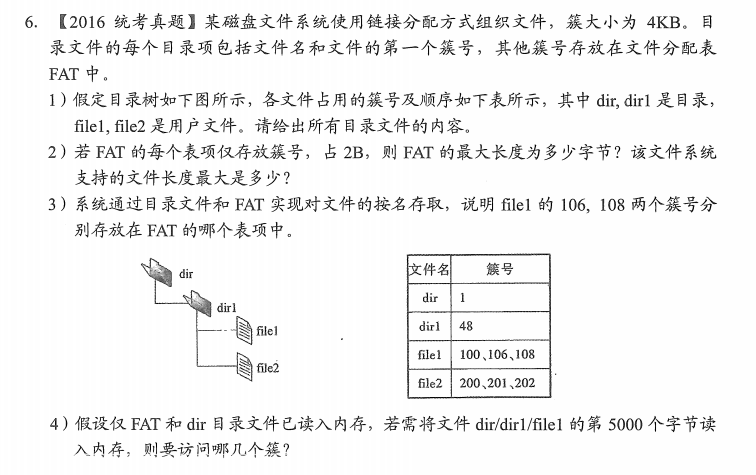
1.dir目录文件
dir1目录文件
| 文件名 |
簇号 |
| file1 |
100 |
| file2 |
200 |
2.2B也就是16位,FAT最多有$2^{16}$个表项,系统也最多有$2^{16}$个块,FAT的最大长度是$2^{16}×2B=128KB$,文件的最大长度是$2^{16}×4KB=256MB$
3.根据FAT的存放标准,每一个块指示下一个块的位置,file1的簇号106存放在FAT的100号表项中,簇号108存放在FAT的106号表项中
4.第5000个字节明显是在第106簇中,已经读入了dir了,所以需要读入dir1的目录文件48号簇和file1的106号簇

- 采用直接索引结构,4TB/1KB=$2^{32}$,32位最少需要4B来表示,那么512B的索引表区最多存储128个表项,128×1KB=128KB,最大长度是128KB
- 块数占了2B,即是16位,$2^{16}$,可以表示$2^{16}$×1KB=$2^{16}$KB,剩下的504B采取直接索引的方式,可储存504/6=84个磁盘,即是84KB,一共是$2^{16}$KB+84KB
扩展单个文件的长度,就是让块数所占的字节尽可能贴近最大块数,调整为4B,即占据32位,和文件里面的物理块数一样,达到文件系统空间上限

- 系统采用顺序分配方式时,插入记录需要移动其他的记录块,整个文件共有 200 条记录,要插入新记录作为第 30 条,而存储区前后均有足够的磁盘空间,且要求最少的访问存储块数,则要把文件前 29 条记录前移,若算访盘次数移动一条记录读出和存回磁盘各是一次访盘,29 条记录共访盘 58 次,存回第 30 条记录访盘 1 次,共访盘 59 次。F 的文件控制区的起始块号和文件长度的内容会因此改变。
- 文件系统采用链接分配方式时,插入记录并不用移动其他记录,只需找到相应的记录,修改指针即可。插入的记录为其第 30 条记录,那么需要找到文件系统的第 29 块,一共需要访盘 29 次,然后把第 29 块的下块地址部分赋给新块,把新块存回内存会访盘 1 次,然后修改内存中第 29 块的下块地址字段,再存回磁盘,一共访盘 31 次。 4 个字节共 32 位,可以寻址 $2^{32}$=4G 块存储块,每块的大小为 1KB,即 1024B,其中下块地址部分占 4B,数据部分占 1020B,那么该系统的文件最大长度是 4G×1020B=4080GB。

关键在于一个簇内能放多少个地址项,4KB/4B=$2^{10}$,最大文件长度为8×4KB+$2^{10}$×10KB+
$2^{20}$×10KB+$2^{30}$×10KB
一个图像文件大小为5600B>4KB,所以会占据两个簇,1个簇里面最多存放4096/64=64个索引节点,则最多有$2^{26}=64M$个索引结点,最大支持64M个图像文件
不相同,因为6KB<32KB,在直接索引结点内,而40KB>32KB,在一级索引结点内
874

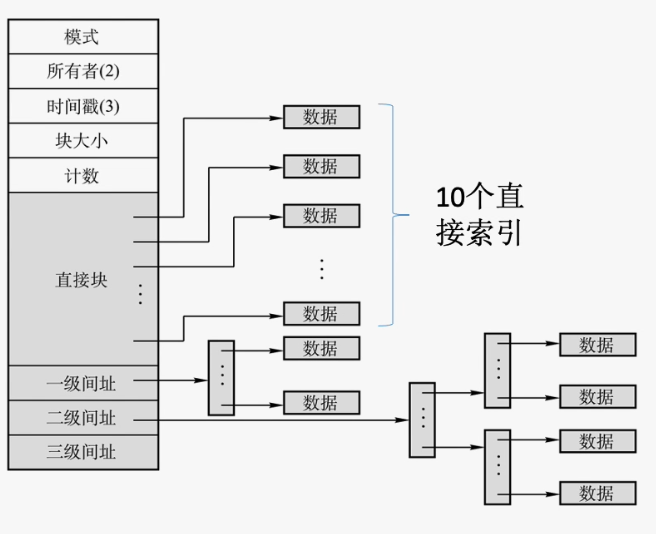
每个数据块可以保存的索引项的数目为:4KB/4B=$2^{10}$,所以能表示的最大文件长度为:
(10+$2^{10}$+$2^{20}$+$2^{30}$)×4KB≈4KB
该文件占用的2GB/4KB=512×1024个数据块
首先直接索引指向了10个数据块,一级间接指引指向了1024个数据块,需要1个索引块,二级索引指向剩下的数据块,即(512×1024-10-1024)个数据块,那么总共需要1+[(512×1024-10-1024)/1024]=512个索引块
索引块所占的空间为:(1+512)×4KB=2MB+4KB
另外,每个文件使用的i_node数据结构占13×4B=52B,故该文件时间占用的磁盘空间大小为2GB+2MB+4KB+52B

首先,簇大小为$2^8$B,每个簇内能放下256/4=64=$2^6$个索引项,所以
最大长度=$(4+2×2^6+2×2^{12})×2^8=1KB+32KB+2MB$
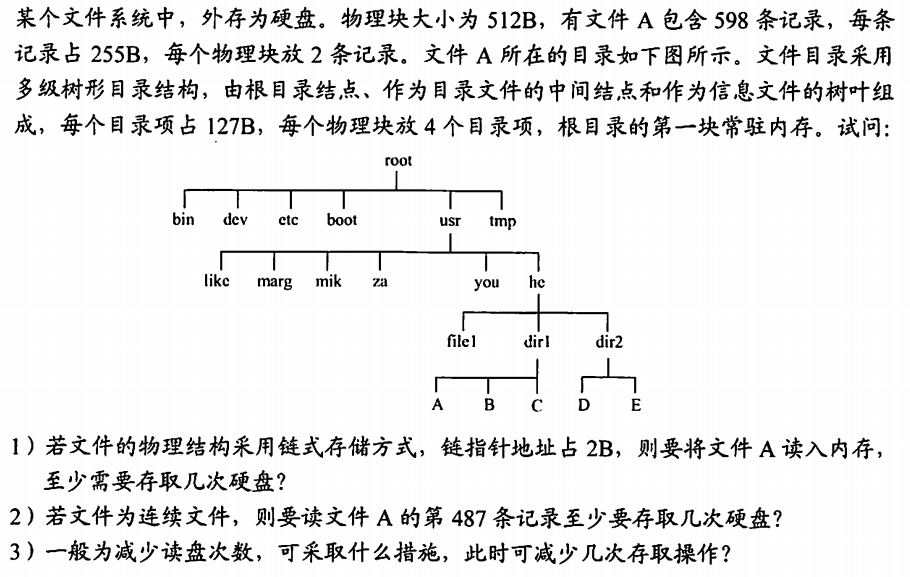
- 每个物理块可放4个目录项和2个记录,要正确读取到usr和you目录,都必须先读取前一个数据块,所以读写dir1的数据块至少要经过2×2+1=5次读取,由于链式存储不具有随机存储的特性,文件A有598条记录,则需要598/2=299块存取,需要299+5=304次存取磁盘
- 如果是连续文件,读写dir1的数据块的次数是一样的,即5次,但读取文件A的第487条记录时可以直接读取,只用1次,所以总的需要1+5=6次
磁盘调度问题

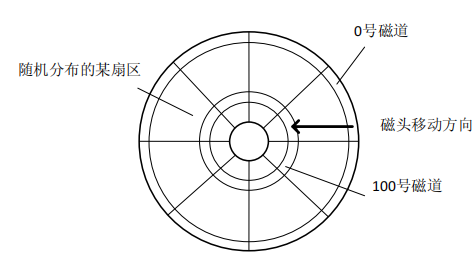
- 16384是$2^{14}$,而2KB的内存空间转为位,也是$2^{14}$位,所以正好可以用位示图法
- 移动磁道的时间为20+90+20+40=170ms,转速为100r/s,旋转延迟为5ms,总的旋转延迟为20ms,读100个扇区的时间为1/(100*100)=0.1ms,总读取时间为0.4ms,总时间为170+20+0.4=190.4ms
- FCFS算法,因为Flash储存器不需要考虑寻道时间和旋转延迟,可以按I/O请求的先后顺序服务

300×10×200×512=300000MB
在85号柱面上,通过计算,85号柱面对应的簇号是85000~85999所以先到100260再到101660,然后访问110560,最后访问60005
物理地址由柱面号,磁头号,扇区号组成
柱面号=100530/1000=100
磁头号=530/100=60
扇区号=(530*2)%200=60
由磁盘驱动程序完成

