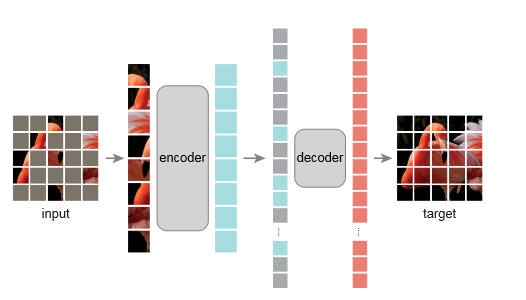
Masked Autoencoders 原理 Masked Autoencoder (MAE) 是一种自监督学习方法,旨在通过预测图像中被随机遮挡部分的内容来学习丰富的视觉特征。它首先将输入图像分割成多个小块(patches),随机遮挡其中一部分,然后利用一个基于Transformer的编码器处理未被遮挡的图像块,通过解码器重建被遮挡的部分。这一过程促使模型捕捉到图像的高级结构和上下文信息,而无需任何外部标签。
预训练完成的编码器随后可以被用于各种下游视觉任务,如图像分类、目标检测等,通过在有标签数据集上进行微调来优化模型性能。MAE通过高效利用未标记数据,显著提升了模型的泛化能力和在各种视觉任务上的表现。
图像分块与遮挡 :
输入图像首先被分割成多个小块(patches)。
随机选择一定比例的图像块进行遮挡(例如,遮挡75%的图像块)。
编码未遮挡的图像块 :
使用基于Transformer的编码器处理未被遮挡的图像块。
编码器专注于未遮挡图像块的特征提取,忽略被遮挡部分。
重建被遮挡的图像块 :
解码器尝试重建整个图像,包括被遮挡的部分。
重建的目标是模拟原始图像的外观,特别是被遮挡的图像块。
自监督学习 :
通过最小化重建图像与原始图像之间的差异(例如,使用均方误差损失函数),模型进行自我学习。
这个过程不需要任何外部的标签信息,完全基于模型自身的预测和实际图像的比较。
预训练模型保存 :
完成自监督预训练后,保存编码器部分的模型。
这个预训练的编码器捕获了图像的通用特征,可以应用于多种视觉任务。
微调应用于下游任务 :
根据具体的下游任务(如图像分类、目标检测等),对预训练的编码器进行微调。
微调过程中,可以替换或添加与特定任务相关的网络层,并在有标签的数据集上进行训练以优化模型的性能。
代码 1 2 3 4 5 from functools import partialimport torchimport torch.nn as nnfrom timm.models.vision_transformer import PatchEmbed, Blockfrom util.pos_embed import get_2d_sincos_pos_embed
timm(PyTorch Image Models)是一个广受欢迎的Python库,专门为深度学习和计算机视觉研究社区设计,基于PyTorch框架。由Ross Wightman创建和维护,它提供了一系列预训练的模型以及训练和验证计算机视觉模型的工具。timm库特别注重于最新的模型架构,包括但不限于卷积神经网络(CNNs)、Transformer模型以及各种混合架构
整体 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 class MaskedAutoencoderViT (nn.Module ): """ Masked Autoencoder with Vision Transformer backbone. 这是一个遮蔽自编码器,使用Vision Transformer作为主干网络。 """ def __init__ (self, img_size=224 , patch_size=16 , in_chans=3 , embed_dim=1024 , depth=24 , num_heads=16 , decoder_embed_dim=512 , decoder_depth=8 , decoder_num_heads=16 , mlp_ratio=4. , norm_layer=nn.LayerNorm, norm_pix_loss=False ): super ().__init__() """ Masked Autoencoder with VisionTransformer backbone. 参数: - img_size (int): 输入图像的大小,方形图像的边长。 - patch_size (int): 图像分割成的小块(patch)的大小,这些小块将被独立处理。 - in_chans (int): 输入图像的通道数,例如,RGB图像为3。 - embed_dim (int): Transformer编码器和解码器的嵌入维度。 - depth (int): 编码器中Transformer块的数量。 - num_heads (int): 多头注意力中的头数。 - decoder_embed_dim (int): 解码器的嵌入维度。 - decoder_depth (int): 解码器中Transformer块的数量。 - decoder_num_heads (int): 解码器的多头注意力中的头数。 - mlp_ratio (float): Transformer内部前馈网络的隐藏层维度与嵌入维度的比例。 - norm_layer (nn.Module): 归一化层的类型,通常是层归一化(LayerNorm)。 - norm_pix_loss (bool): 是否对像素级损失应用归一化。 """ self.patch_embed = PatchEmbed(img_size, patch_size, in_chans, embed_dim) num_patches = self.patch_embed.num_patches self.cls_token = nn.Parameter(torch.zeros(1 , 1 , embed_dim)) self.pos_embed = nn.Parameter(torch.zeros(1 , num_patches + 1 , embed_dim), requires_grad=False ) self.blocks = nn.ModuleList([ Block(embed_dim, num_heads, mlp_ratio, qkv_bias=True , qk_scale=None , norm_layer=norm_layer) for i in range (depth)]) """ - embed_dim (int): 嵌入维度,表示输入特征向量的大小。 - num_heads (int): 多头注意力机制中的头数。 - mlp_ratio (float): 多层感知机(MLP)的隐藏层与输入层维度的比率。 - qkv_bias (bool): 指示在计算查询(Q)、键(K)和值(V)向量时是否添加偏置(bias)。 - qk_scale (Optional[float]): 查询(Q)和键(K)的点积缩放因子。 - norm_layer (nn.Module): 归一化层,用于Transformer块内部。 """ self.norm = norm_layer(embed_dim) self.decoder_embed = nn.Linear(embed_dim, decoder_embed_dim, bias=True ) self.mask_token = nn.Parameter(torch.zeros(1 , 1 , decoder_embed_dim)) self.decoder_pos_embed = nn.Parameter(torch.zeros(1 , num_patches + 1 , decoder_embed_dim), requires_grad=False ) self.decoder_blocks = nn.ModuleList([ Block(decoder_embed_dim, decoder_num_heads, mlp_ratio, qkv_bias=True , qk_scale=None , norm_layer=norm_layer) for i in range (decoder_depth)]) self.decoder_norm = norm_layer(decoder_embed_dim) self.decoder_pred = nn.Linear(decoder_embed_dim, patch_size**2 * in_chans, bias=True ) self.norm_pix_loss = norm_pix_loss self.initialize_weights()
这里直接使用timm库中的PatchEmbed方法,把图片划分为块,同时使用了Block方法,Block表示Attention+FFN的组合,也就是Transformer中编码器的一个块
初始化权重 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def initialize_weights (self ): pos_embed = get_2d_sincos_pos_embed(self.pos_embed.shape[-1 ], int (self.patch_embed.num_patches ** .5 ), cls_token=True ) self.pos_embed.data.copy_(torch.from_numpy(pos_embed).float ().unsqueeze(0 )) decoder_pos_embed = get_2d_sincos_pos_embed(self.decoder_pos_embed.shape[-1 ], int (self.patch_embed.num_patches ** .5 ), cls_token=True ) self.decoder_pos_embed.data.copy_(torch.from_numpy(decoder_pos_embed).float ().unsqueeze(0 )) w = self.patch_embed.proj.weight.data torch.nn.init.xavier_uniform_(w.view([w.shape[0 ], -1 ])) torch.nn.init.normal_(self.cls_token, std=.02 ) torch.nn.init.normal_(self.mask_token, std=.02 ) self.apply(self._init_weights)
initialize_weights函数pos_embed和decoder_pos_embed)、patch嵌入的投影层、类别标记(cls_token)和遮蔽标记(mask_token)。这些组件由于其特殊的作用(如位置嵌入需要捕捉序列位置信息,类别标记需要代表全局信息)而需要采用特定的初始化方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def _init_weights (self, m ): if isinstance (m, nn.Linear): torch.nn.init.xavier_uniform_(m.weight) if m.bias is not None : nn.init.constant_(m.bias, 0 ) elif isinstance (m, nn.LayerNorm): nn.init.constant_(m.bias, 0 ) nn.init.constant_(m.weight, 1.0 )
_init_weights函数nn.Linear)和层归一化层(nn.LayerNorm)。通过使用apply方法,这个函数被递归地应用于模型的所有子模块,实现了代码的复用和结构的简化。
分块和重构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 def patchify (self, imgs ): """ 将图像分割成小块(patches)。 参数: - imgs: 输入图像,形状为(N, 3, H, W),其中N是批大小,3代表颜色通道,H和W是图像的高度和宽度。 返回: - x: 分割后的图像块,形状为(N, L, patch_size**2 * 3),其中L是图像分割成的块数,`patch_size**2 * 3`是每个块的平面化尺寸。 """ p = self.patch_embed.patch_size[0 ] assert imgs.shape[2 ] == imgs.shape[3 ] and imgs.shape[2 ] % p == 0 h = w = imgs.shape[2 ] // p x = imgs.reshape(shape=(imgs.shape[0 ], 3 , h, p, w, p)) x = torch.einsum('nchpwq->nhwpqc' , x) x = x.reshape(shape=(imgs.shape[0 ], h * w, p ** 2 * 3 )) return x def unpatchify (self, x ): """ 将图像块(patches)重构回原始图像形状。 参数: - x: 分割的图像块,形状为(N, L, patch_size**2 * 3),其中L是图像分割成的块数。 返回: - imgs: 重构后的图像,形状为(N, 3, H, W),H和W是重构后的图像的高度和宽度。 """ p = self.patch_embed.patch_size[0 ] h = w = int (x.shape[1 ] ** .5 ) assert h * w == x.shape[1 ] x = x.reshape(shape=(x.shape[0 ], h, w, p, p, 3 )) x = torch.einsum('nhwpqc->nchpwq' , x) imgs = x.reshape(shape=(x.shape[0 ], 3 , h * p, h * p)) return imgs
这里的分块方法是为了在最后比较误差,给原图像分块的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 def random_masking (self, x, mask_ratio ): """ 对每个样本执行随机遮蔽,通过对每个样本的随机噪声进行argsort来实现样本内部的随机排序。 参数: - x: 输入序列,形状为[N, L, D],其中N是批次大小,L是序列长度,D是特征维度。 - mask_ratio: 遮蔽比例,即要遮蔽的序列部分所占的比例。 返回: - x_masked: 遮蔽后保留的序列部分,形状为[N, len_keep, D],len_keep是根据mask_ratio计算的保留序列长度。 - mask: 二进制遮蔽,形状为[N, L],其中0表示保留的元素,1表示被遮蔽的元素。 - ids_restore: 用于还原序列原始顺序的索引,形状为[N, L]。 """ N, L, D = x.shape len_keep = int (L * (1 - mask_ratio)) noise = torch.rand(N, L, device=x.device) ids_shuffle = torch.argsort(noise, dim=1 ) ids_restore = torch.argsort(ids_shuffle, dim=1 ) ids_keep = ids_shuffle[:, :len_keep] x_masked = torch.gather(x, dim=1 , index=ids_keep.unsqueeze(-1 ).repeat(1 , 1 , D)) mask = torch.ones([N, L], device=x.device) mask[:, :len_keep] = 0 mask = torch.gather(mask, dim=1 , index=ids_restore) return x_masked, mask, ids_restore
掩蔽分块后的图像
编码器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 def forward_encoder (self, x, mask_ratio ): """ 编码器的前向传播过程。 参数: - x: 输入图像,形状为[N, C, H, W],其中N是批次大小,C是通道数,H和W是图像的高度和宽度。 - mask_ratio: 遮蔽比例,定义了输入中有多少比例的数据将被随机遮蔽。 返回: - x: 经过Transformer编码器处理后的特征表示,形状为[N, L+1, D],L是序列长度,D是特征维度。 - mask: 应用于输入的二进制遮蔽,形状为[N, L],0表示保留的元素,1表示被遮蔽的元素。 - ids_restore: 用于还原序列原始顺序的索引,形状为[N, L]。 """ x = self.patch_embed(x) x = x + self.pos_embed[:, 1 :, :] x, mask, ids_restore = self.random_masking(x, mask_ratio) cls_token = self.cls_token + self.pos_embed[:, :1 , :] cls_tokens = cls_token.expand(x.shape[0 ], -1 , -1 ) x = torch.cat((cls_tokens, x), dim=1 ) for blk in self.blocks: x = blk(x) x = self.norm(x) return x, mask, ids_restore
解码器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def forward_decoder (self, x, ids_restore ): x = self.decoder_embed(x) mask_tokens = self.mask_token.repeat(x.shape[0 ], ids_restore.shape[1 ] + 1 - x.shape[1 ], 1 ) x_ = torch.cat([x[:, 1 :, :], mask_tokens], dim=1 ) x_ = torch.gather(x_, dim=1 , index=ids_restore.unsqueeze(-1 ).repeat(1 , 1 , x.shape[2 ])) x = torch.cat([x[:, :1 , :], x_], dim=1 ) x = x + self.decoder_pos_embed for blk in self.decoder_blocks: x = blk(x) x = self.decoder_norm(x) x = self.decoder_pred(x) x = x[:, 1 :, :] return x
计算损失 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def forward_loss (self, imgs, pred, mask ): """ 计算重建损失。 参数: - imgs: 原始图像,形状为[N, 3, H, W],其中N是批次大小,3代表颜色通道,H和W是图像的高度和宽度。 - pred: 解码器预测的重建图像,形状为[N, L, p*p*3],其中L是图像分割成的小块数,p是每个块的大小,p*p*3代表每个块的平展开的像素值。 - mask: 二进制遮蔽标记,形状为[N, L],其中0表示保留的块,1表示被遮蔽(移除)的块。 返回: - loss: 计算得到的重建损失,为被遮蔽块的平均损失。 """ target = self.patchify(imgs) if self.norm_pix_loss: mean = target.mean(dim=-1 , keepdim=True ) var = target.var(dim=-1 , keepdim=True ) target = (target - mean) / (var + 1.e-6 ) ** .5 loss = (pred - target) ** 2 loss = loss.mean(dim=-1 ) loss = (loss * mask).sum () / mask.sum () return loss
前向传播 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def forward (self, imgs, mask_ratio=0.75 ): """ 模型的前向传播过程。 参数: - imgs: 输入的原始图像,形状为[N, 3, H, W]。 - mask_ratio: 遮蔽比例,定义了有多少比例的图像块将被随机遮蔽。 返回: - loss: 计算得到的重建损失。 - pred: 解码器预测的重建图像,形状为[N, L, p*p*3]。 - mask: 应用于输入的二进制遮蔽标记,形状为[N, L]。 """ latent, mask, ids_restore = self.forward_encoder(imgs, mask_ratio) pred = self.forward_decoder(latent, ids_restore) loss = self.forward_loss(imgs, pred, mask) return loss, pred, mask