
ViT
Vision in Transformer
原理
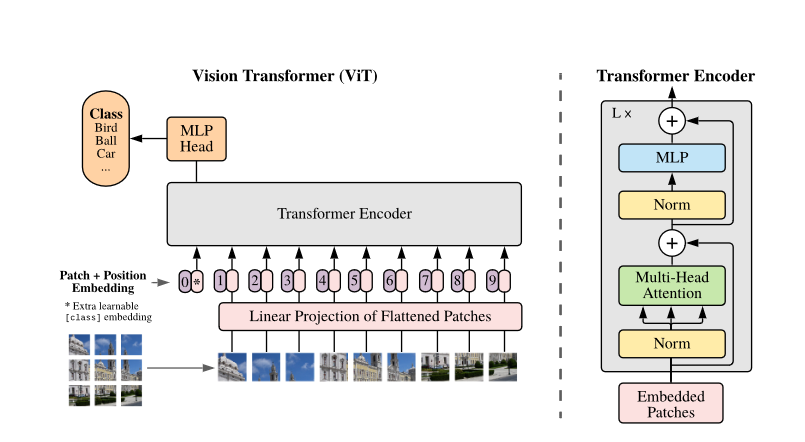
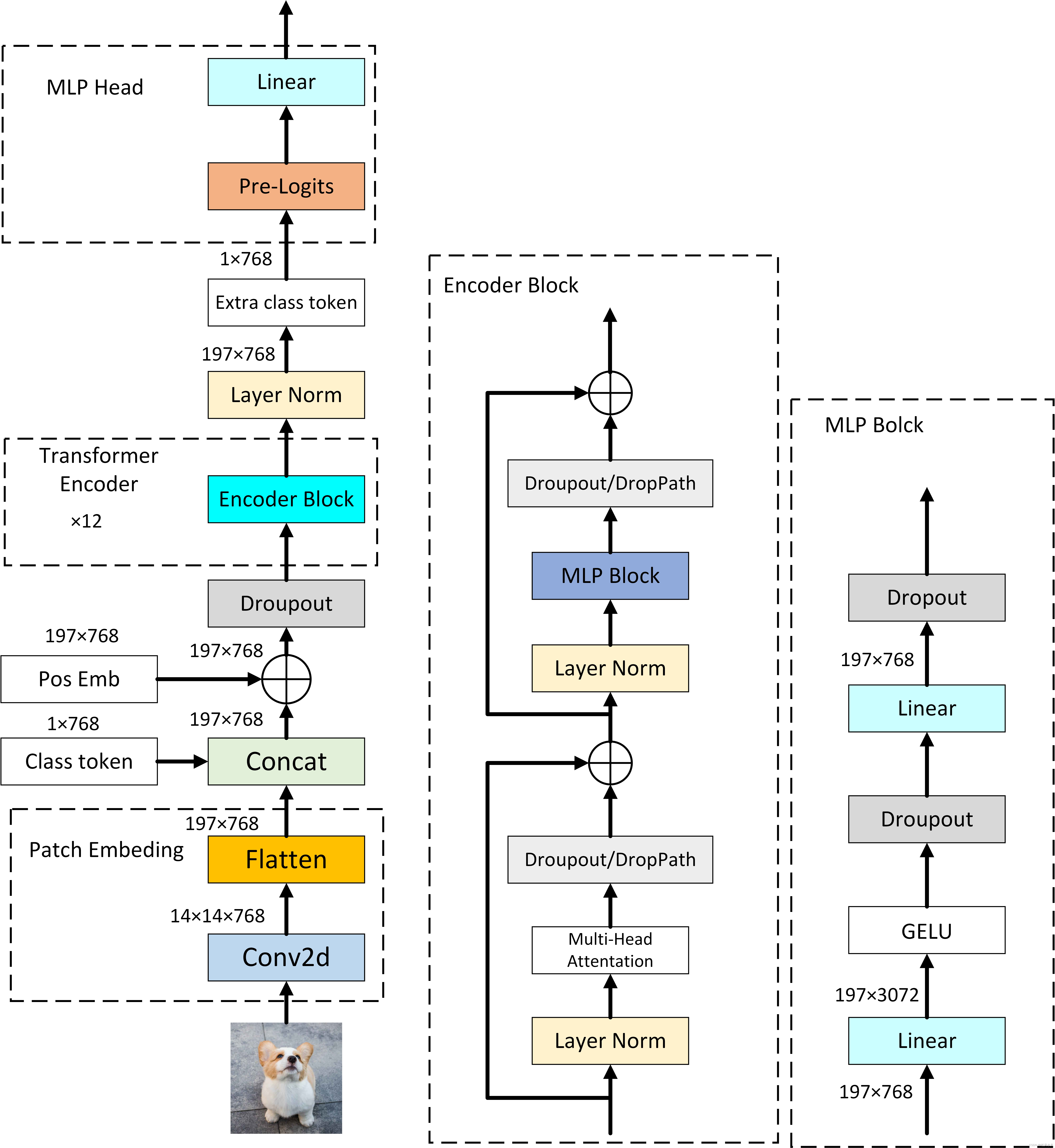
从架构图可以看出,ViT主要步骤如下:
- Patch Embedding:首先,对原始输入图像作切块处理。假设输入的图像大小为224×224,我们将图像切成一个个固定大小为16×16的方块,每一个小方块就是一个patch,那么每张图像中patch的个数为(224×224)/(16×16) = 196个。切块后,我们得到了196个[16, 16, 3]的patch,我们把这些patch送入Linear Projection of Flattened Patches(Embedding层),这个层的作用是将输入序列展平。所以输出后也有196个token,每个token的维度经过展平后为16×16×3 = 768,所以输出的维度为[196, 768]。不难看出,Patch Embedding的作用是将一个CV问题通过切块和展平转化为一个NLP问题。
- Position Embedding: 我们知道,图像的每个patch和文本一样,也有先后顺序,是不能随意打乱的,所以我们需要再给每个token添加位置信息。类比BERT模型,我们还需要添加一个特殊字符class token。那么,最终要输入到Transformer Encoder的序列维度为[197, 768]。Position Embedding的作用是添加位置信息。
- Transformer Encoder:将维度为[197, 768]的序列输入到标准的Transformer Encoder中。
- MLP Head:Transformer Encoder的输出其实也是一个序列,但是在ViT模型中只使用了class token的输出,将其送入MLP模块中,最终输出分类结果。MLP Head的作用是用于最终的分类。
动图版本:
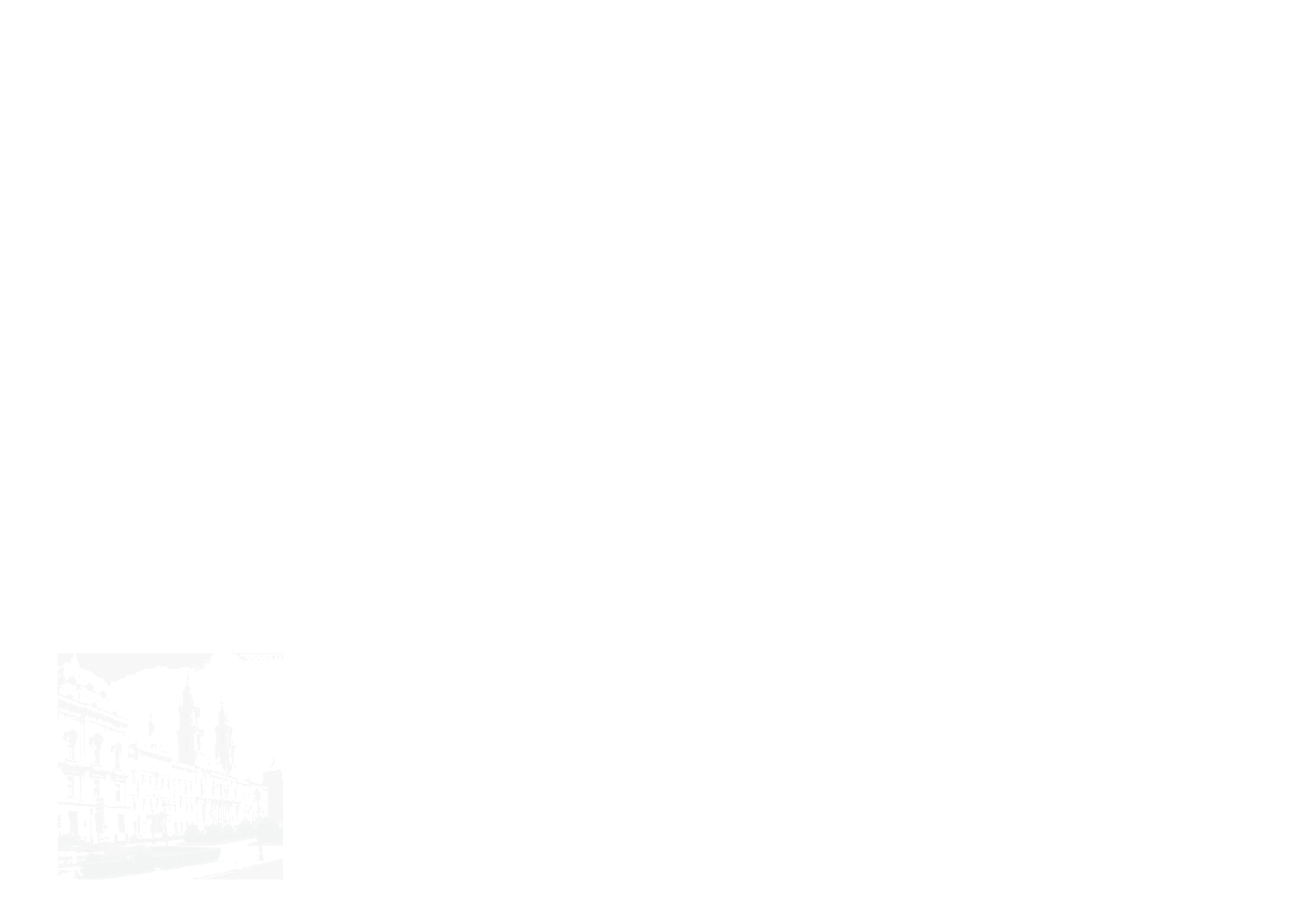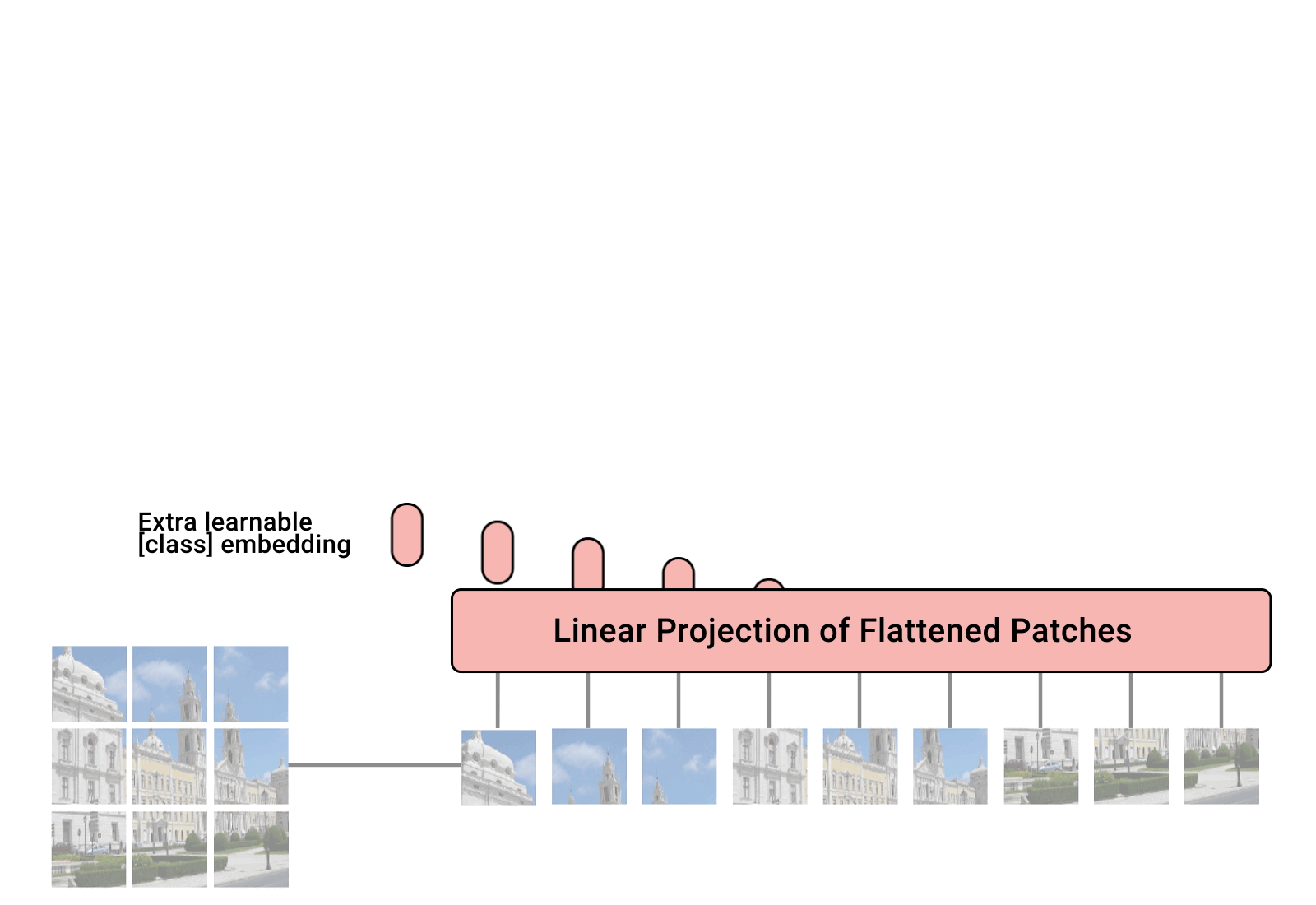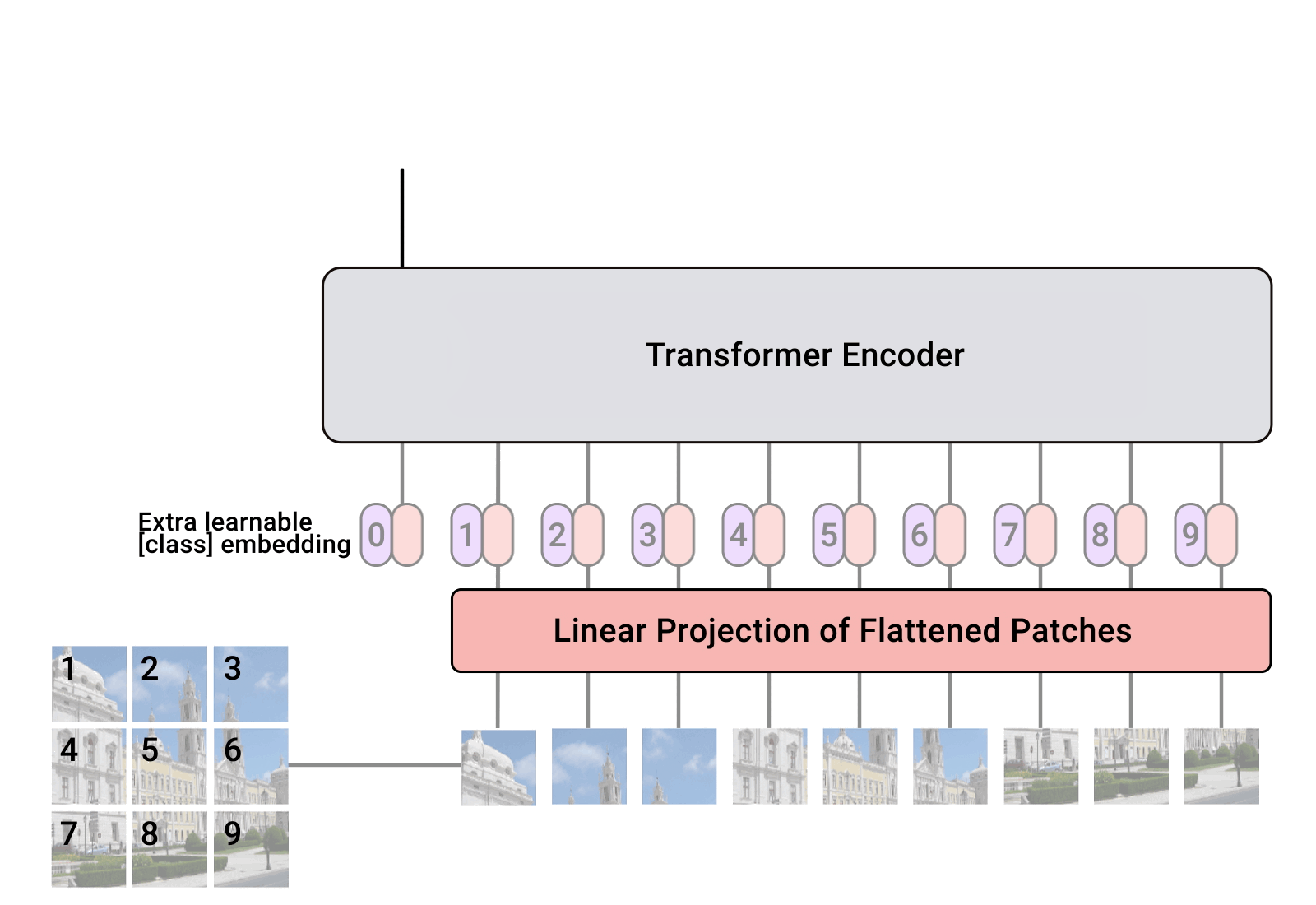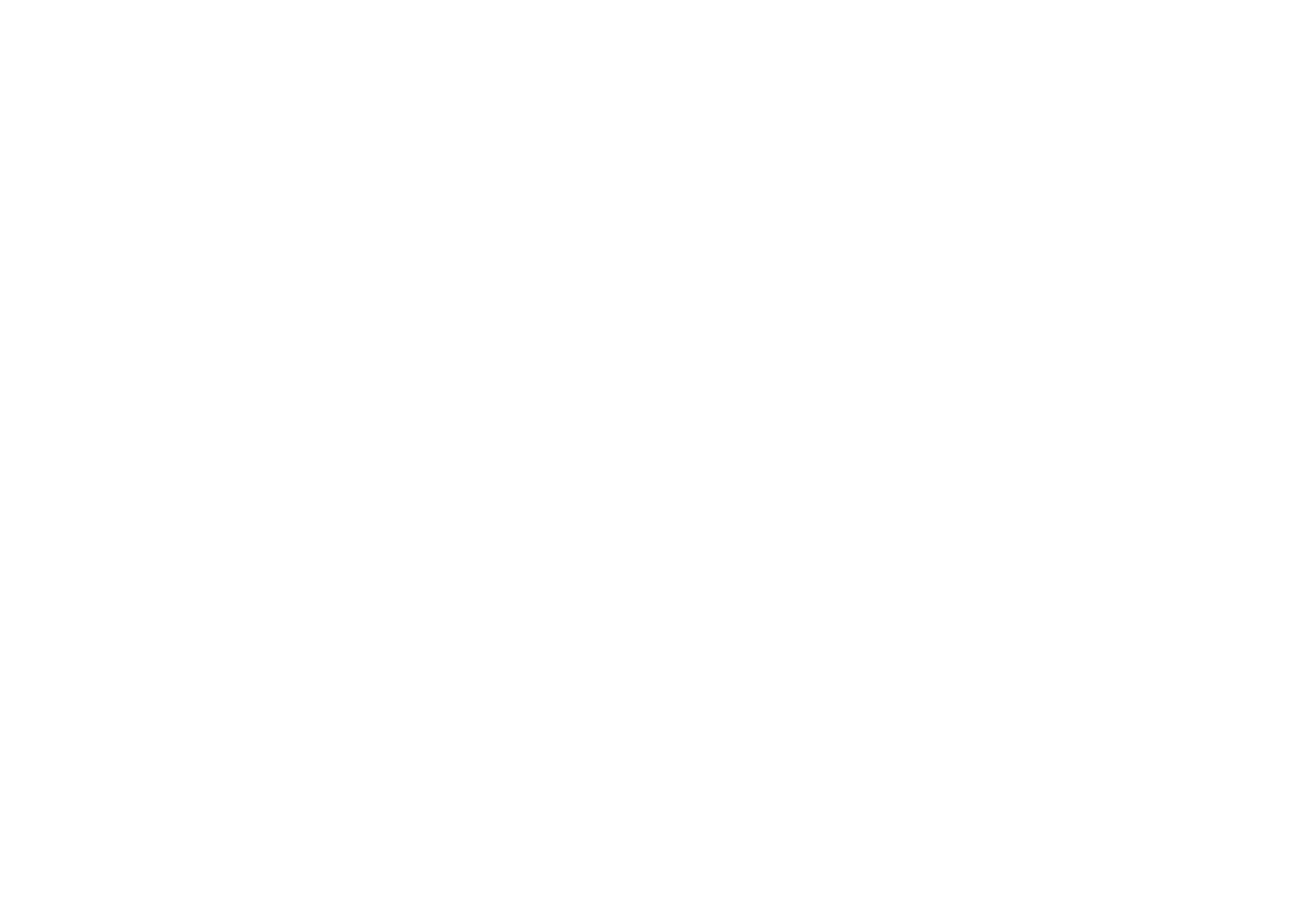
程序流程图:
代码分析
drop_path技术
1 | def drop_path(x, drop_prob: float = 0., training: bool = False): |
PatchEmbed层
1 | class PatchEmbed(nn.Module): |
重点是分析proj这个卷积层的作用:
输入
- 输入数据: 输入到这个卷积层的数据是一个四维张量,形状为
[B, C, H, W],其中:B是批量大小,表示一次处理多少个图像。C是通道数,对于彩色RGB图像,C=3。H和W是图像的高度和宽度,都是244
卷积层配置
- 卷积核大小 (
kernel_size): 与补丁的大小相同,即16x16。这意味着每次卷积操作都会覆盖16x16的像素区域。 - 步长 (
stride): 同样设置为补丁的大小,即16。这确保了每次卷积操作之后都会移动一个补丁的大小,没有重叠部分,从而直接将图像分割成大小相等的补丁。 - 输入通道数 (
in_channels): 等于输入数据的通道数,对于RGB图像来说是3。 - 输出通道数 (
out_channels): 这是嵌入维度,例子中是768。这表示每个补丁都会被映射到一个768维的向量。
输出
- 输出数据: 经过卷积层处理后,输出数据的形状将会是
[B, embed_dim, grid_H, grid_W],其中:B是批量大小,与输入相同。embed_dim是输出通道数,即嵌入维度,你的例子中是768。grid_H和grid_W是经过卷积层处理后的图像高度和宽度在补丁维度上的大小。由于原始图像尺寸为224x224,补丁大小为16x16,所以grid_H和grid_W都是14(224/16=14),这意味着每个维度上都有14个补丁
展平并转置
flatten(2)操作是将每个补丁的嵌入向量展平。这里的2指的是从第三维开始平铺(因为维度是从0开始计数的,所以0对应于批次维度B,1对应于嵌入维度embed_dim)。因此,flatten(2)操作是将每个补丁的嵌入向量平铺开来,结果的形状变为[B, embed_dim, num_patches],其中num_patches是总的补丁数量(即grid_size[0] * grid_size[1])- 最后,
.transpose(1, 2)操作是将第二维和第三维交换。由于在flatten(2)之后,我们得到的维度是[B, embed_dim, num_patches],我们需要将嵌入向量的维度(embed_dim)和补丁数量的维度(num_patches)交换,以使得每个补丁的嵌入向量在序列的第二维度上。这样做的目的是为了让输出的形状与后续Transformer网络的输入要求相匹配。转置后,输出的形状是[B, num_patches, embed_dim]。
Decoder-Attention层
1 | class Attention(nn.Module): |
Decoder-MLP层
1 | class Mlp(nn.Module): |
Decoder层
1 | class Block(nn.Module): |
权重初始化
1 | def _init_vit_weights(m): |
整体架构
1 | class VisionTransformer(nn.Module): |
- 表示层(Representation Layer):如果
representation_size被设置,这表明在模型的最后,希望通过一个额外的全连接层(fc)和激活函数(act,这里使用的是Tanh)来处理logits。这可以用于降维或学习一个更加紧凑的特征表示。如果不进行蒸馏(distilled为False),这个层会被激活。 - 分类头(Classification Head):这是模型的最后一层,负责将特征表示(
logits)映射到类别预测上。这里使用的是一个线性层nn.Linear,其输出大小为num_classes,表示不同类别的预测logits - 蒸馏头(Distillation Head):如果进行模型蒸馏(
distilled为True),则会添加一个蒸馏头head_dist。蒸馏头的作用是在训练时学习从教师模型转移过来的知识,通常用于提高模型的泛化能力或压缩模型。
分类的具体过程:
当模型的前向传播方法forward_features被调用时,它返回了一个包含cls_token和所有补丁嵌入的合并序列。这个序列的形状为[B, N+1, C],其中:
B是批次大小(batch size),N是补丁的数量,C是嵌入的维度(embed_dim),N+1中的+1代表了额外的cls_token。
在代码中,x[:, 0]用于选取每个序列中位置0上的元素,即cls_token对应的特征向量。由于cls_token被放在序列的第一个位置,x[:, 0]能够精确地选取出这个全局表示向量。这样做的结果是,对于批次中的每个图像,我们都得到了一个代表其全局信息的向量,形状为[B, C]:
B代表批次中图像的数量,C代表特征向量的维度。
接下来,这个[B, C]形状的特征向量被送入分类头(即全连接层self.head),进行最终的类别预测。全连接层将特征向量从C维映射到类别数num_classes维,输出的形状变为[B, num_classes],其中每一行包含了对应图像属于每个类别的预测分数。
总结
在Vision Transformer (ViT)中,预测过程是这样进行的:
输入图像预处理
输入: 首先,输入图像的尺寸为
224x224,颜色通道为3(RGB)。因此,每个图像的原始张量形状为[3, 224, 224]。批处理: 如果我们有N个这样的图像,组成一个批次进行处理,那么输入张量的形状将为
[N, 3, 224, 224]。
图像切分为补丁
补丁化: 每个图像被切分成16x16的小块,即补丁。因为每边可以分为14个这样的补丁(224 / 16 = 14),总共有
14 * 14 = 196个补丁。补丁形状: 每个补丁被展平,展平后的维度为
3 * 16 * 16 = 768,因此每个图像转换为196个这样的768维向量。补丁化后的形状: 对整个批次而言,补丁化后的张量形状为
[N, 196, 768]。
类别嵌入
在补丁序列的前面加入一个特殊的类别嵌入(类似于BERT中的[CLS]标记),这个嵌入是可学习的,旨在最终被用于分类。
添加类别嵌入后: 张量的形状变为
[N, 197, 768],因为每个图像序列前都添加了一个额外的768维向量。
通过Transformer编码器
编码: 这197个向量(包括196个补丁向量和1个类别嵌入向量)被送入一系列Transformer编码器层。这些层通过自注意力机制和前馈网络,能够捕捉补丁之间的复杂关系。
保持形状不变: 经过Transformer层处理后,输出张量的形状仍为
[N, 197, 768],但是包含了丰富的上下文信息。
预测头
提取类别嵌入: 对于分类任务,我们关注的是类别嵌入(即序列中的第一个向量)。这个向量现在包含了经过整个图像处理和编码后的全局信息。
预测: 类别嵌入被送入一个预测头(通常是一个或多个全连接层),这个预测头将768维的向量映射到最终的类别数上,假设这里是5。
输出形状: 经过预测头处理后,每个图像的输出形状为
[5],代表5个类别的概率分布。批次输出形状: 对整个批次而言,输出张量的形状为
[N, 5]。
结果解析
- 概率分布: 输出张量的每一行代表一个图像对应的5个类别的概率分布。这个分布可以通过
softmax函数获得,确保所有概率之和为1。 - 分类决策: 最终的分类决策通常是选取概率最高的类别作为预测结果
总结来说,从输入图像到最终的分类预测,Vision Transformer通过将图像切分成补丁、添加类别嵌入、利用Transformer编码器捕捉补丁间的关系,最后通过预测头输出每个类别的概率,从而实现从图像到类别标签的映射。
