
10.0.支持向量机
支持向量机
直觉理解
硬间隔
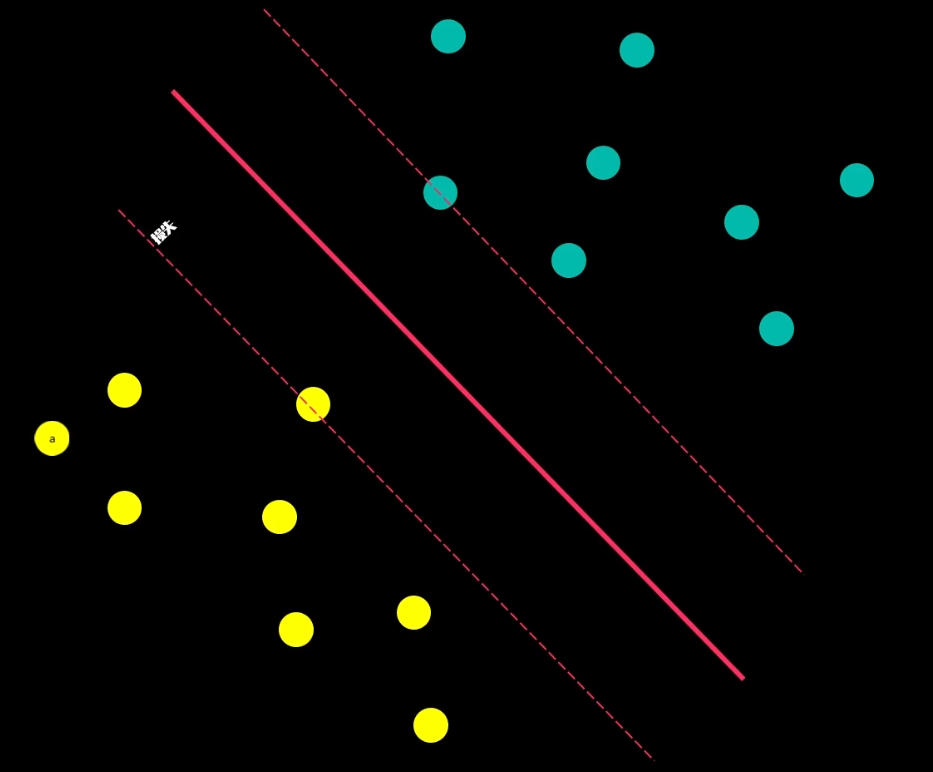
具体而言,如果你考察这样一个数据集,其中有正样本,也有负样本,可以看到这个数据集是线性可分的。我的意思是,存在一条直线把正负样本分开。当然有多条不同的直线,可以把正样本和负样本完全分开。
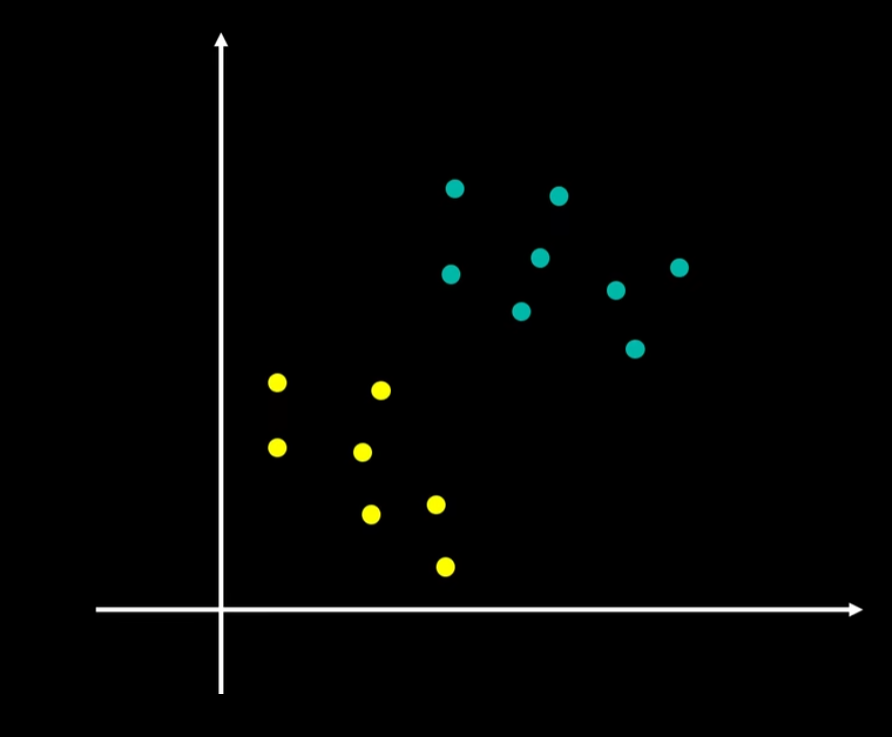
那么该如何选择哪一条直线来划分数据?
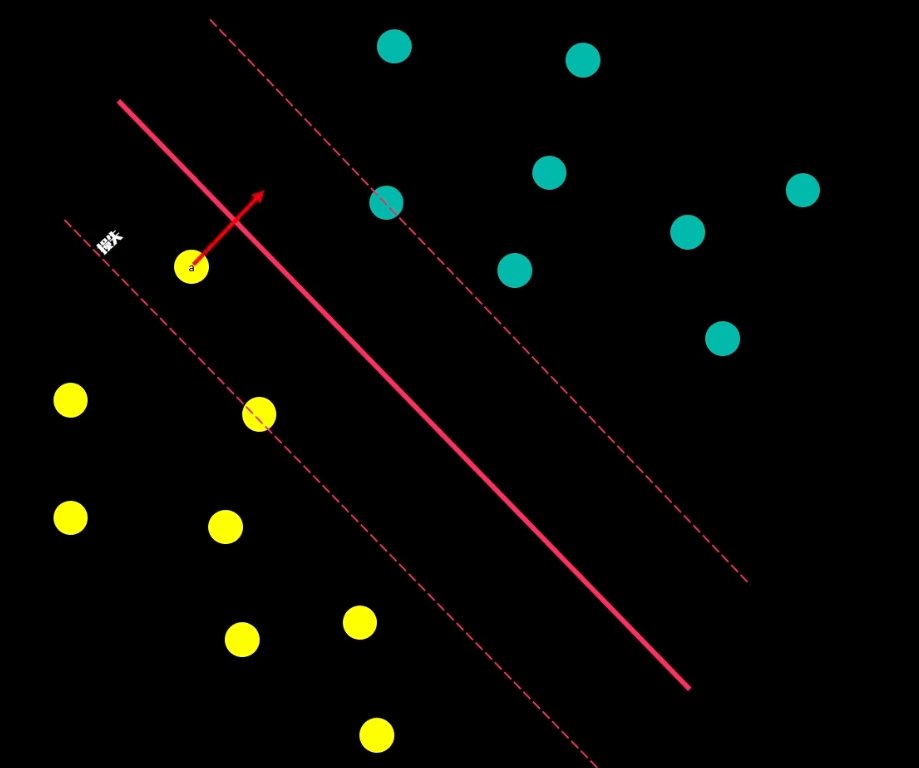
从直觉来说,应该在数据中间画一条直线,如下图所示:
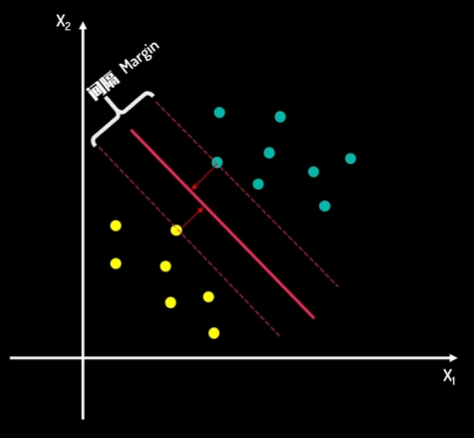
在这种画法中,两类数据中所有的点,都与这条线保持了一定的距离,这个距离起到了缓冲区的作用,当这个距离足够大时,分类结果的可信度也就足够高了,把这个缓冲区称为:间隔
间隔距离体现了两类数据的差异大小,间隔的正中,就是决策边界,寻找最佳决策边界线的问题可以转化为求解两类数据的最大间隔问题
而当有新数据需要判断时,根据新数据处于决策边界的相对位置,就可以进行分类
假设决策边界的超平面公式为:
然后我们平移决策边界,由于平移过程中一定会经过数据的点,而上下最先接触到的点决定了间隔距离,我们称之为支持向量
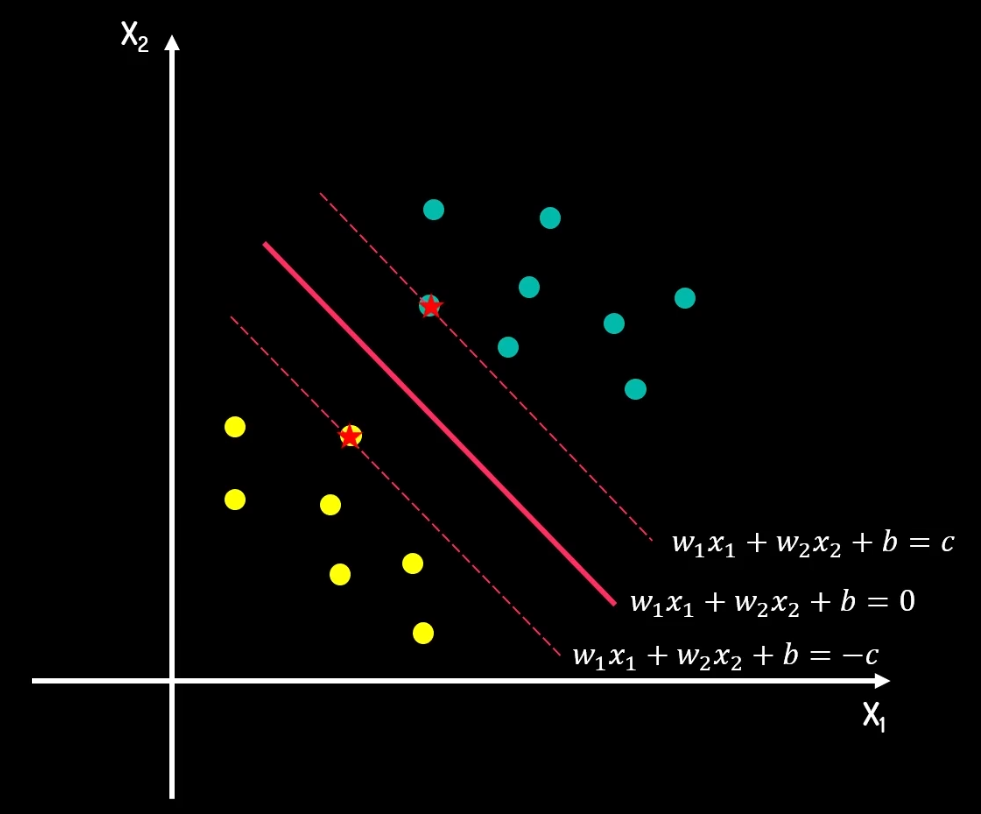
其上下边界的方程式为:
等式两边同时除以c
因为c是常数,实际上可以直接写成
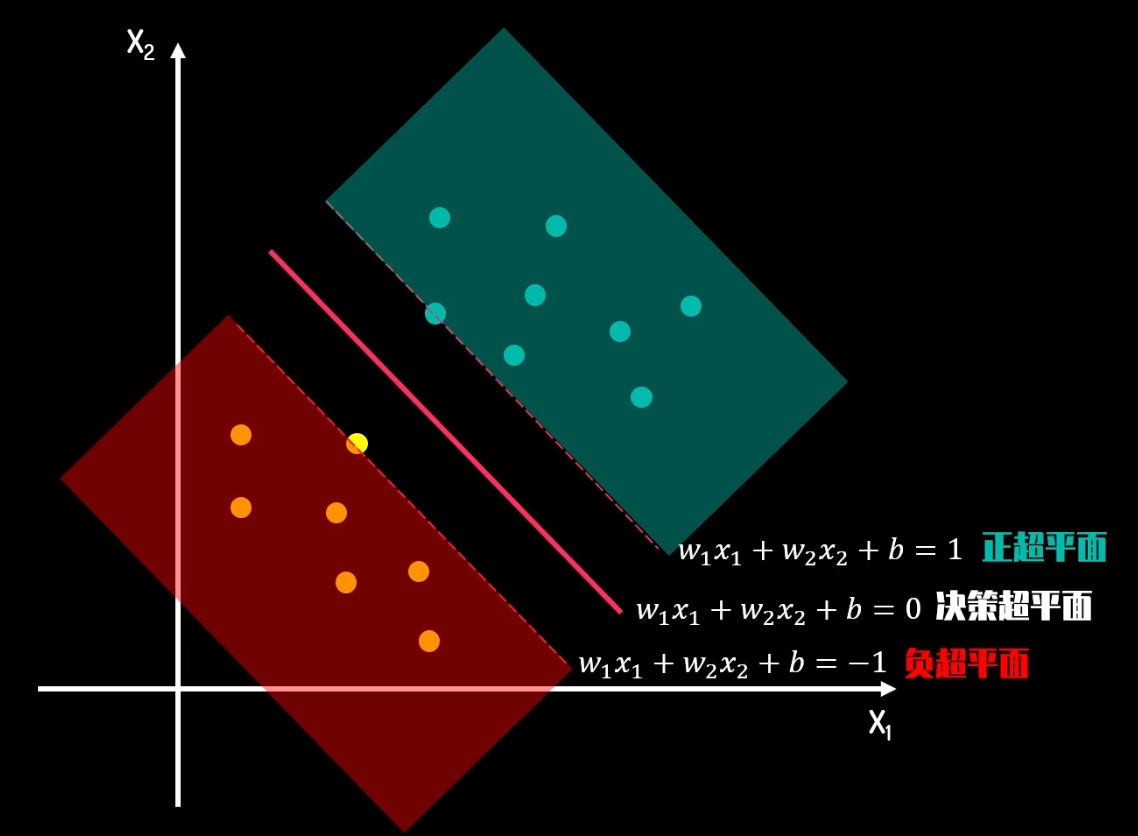
这种间隔称之为硬间隔,具体定义如下:
硬间隔(Hard Margin)是指在支持向量机(SVM)中,对于线性可分的数据集,找到一个能够完美分隔两个类别的决策边界,使得每个训练样本都正确分类,且离决策边界的距离(间隔)最大。硬间隔 SVM 被用于处理线性可分的情况。
硬间隔的目标是使得决策边界两侧的支持向量到决策边界的距离(间隔)最大化,以确保对于未见过的样本,有更大的容错空间,从而提高模型的泛化性能。这个最大间隔的决策边界通常位于支持向量之间,这也解释了为什么这个方法叫做“硬间隔”,因为它对于训练数据的分类是非常严格的。
软间隔
假如初始数据发生了如下变化:
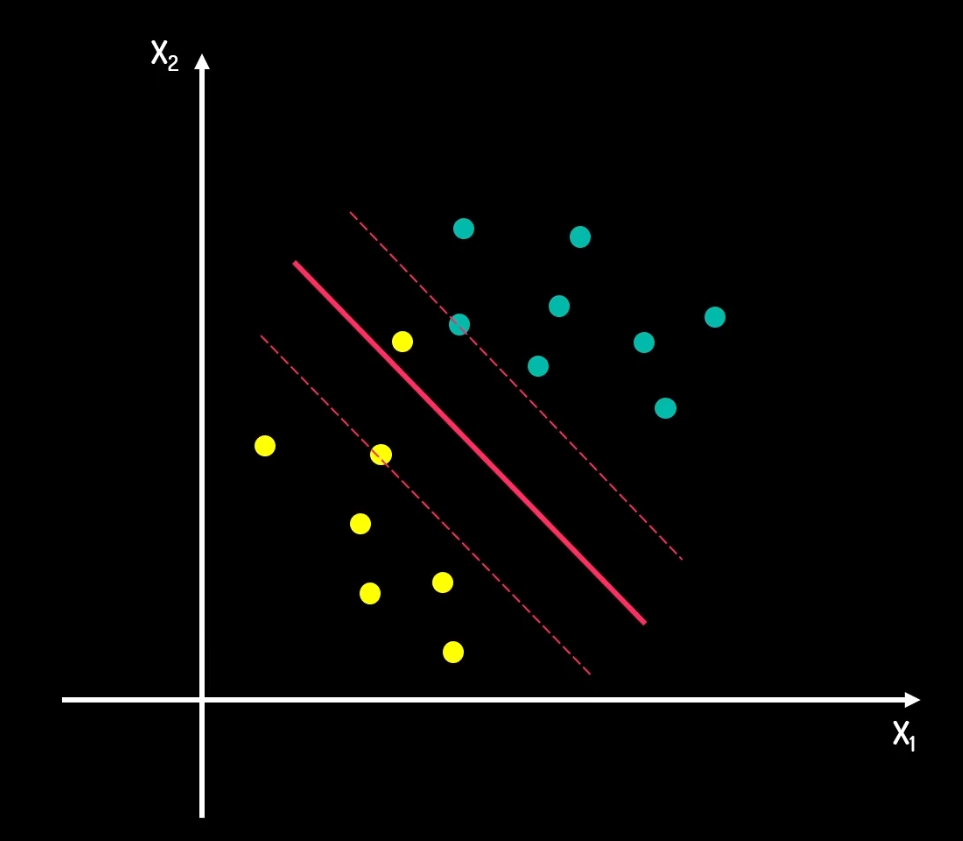
那么按照硬间隔的划分方法,实际上会这个样子:
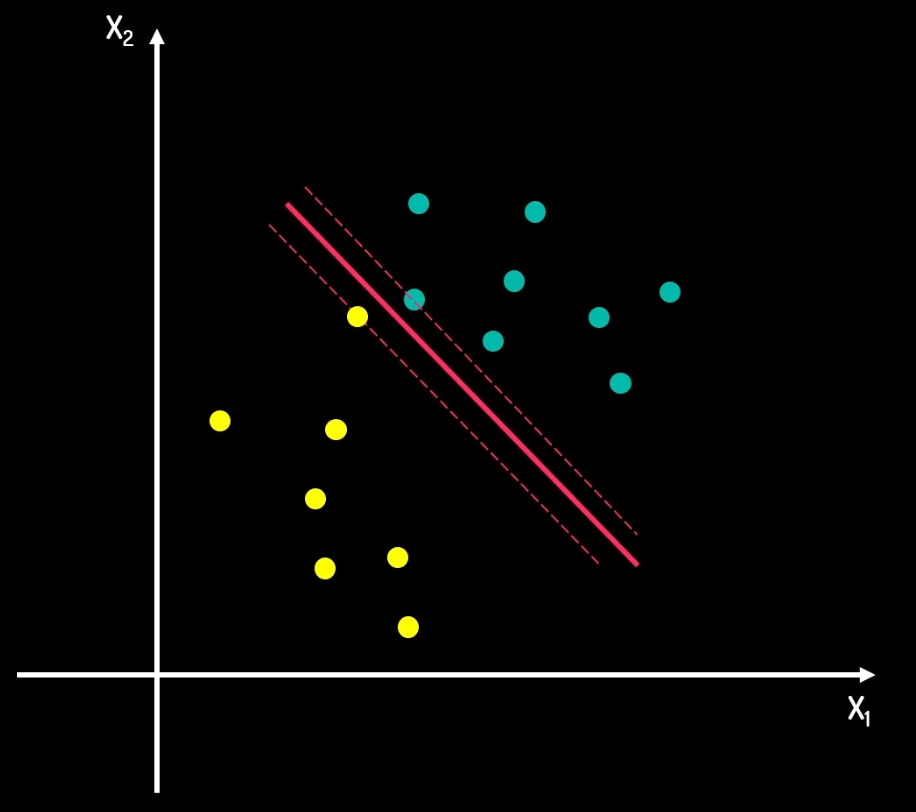
这显然不对,当有很多异常值的时候,硬间隔就会变得非常难找,所以需要引入损失函数cost的概念
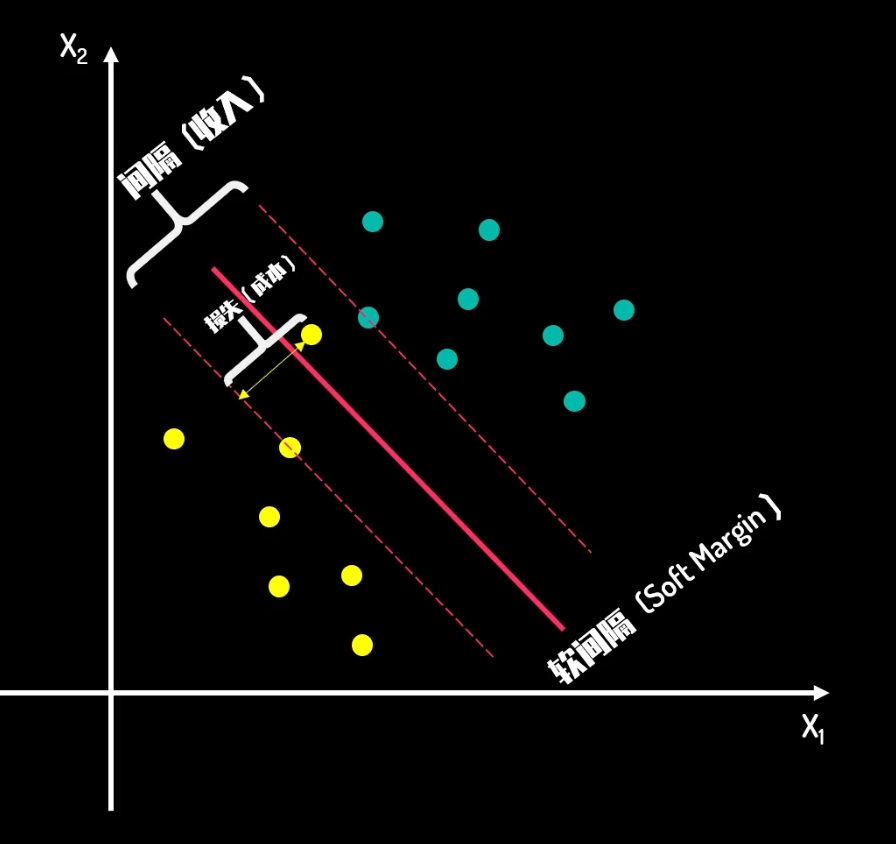
问题就转换为了,考虑损失的情况下,如何最大化间隔,而这种情况下的间隔,称为软间隔
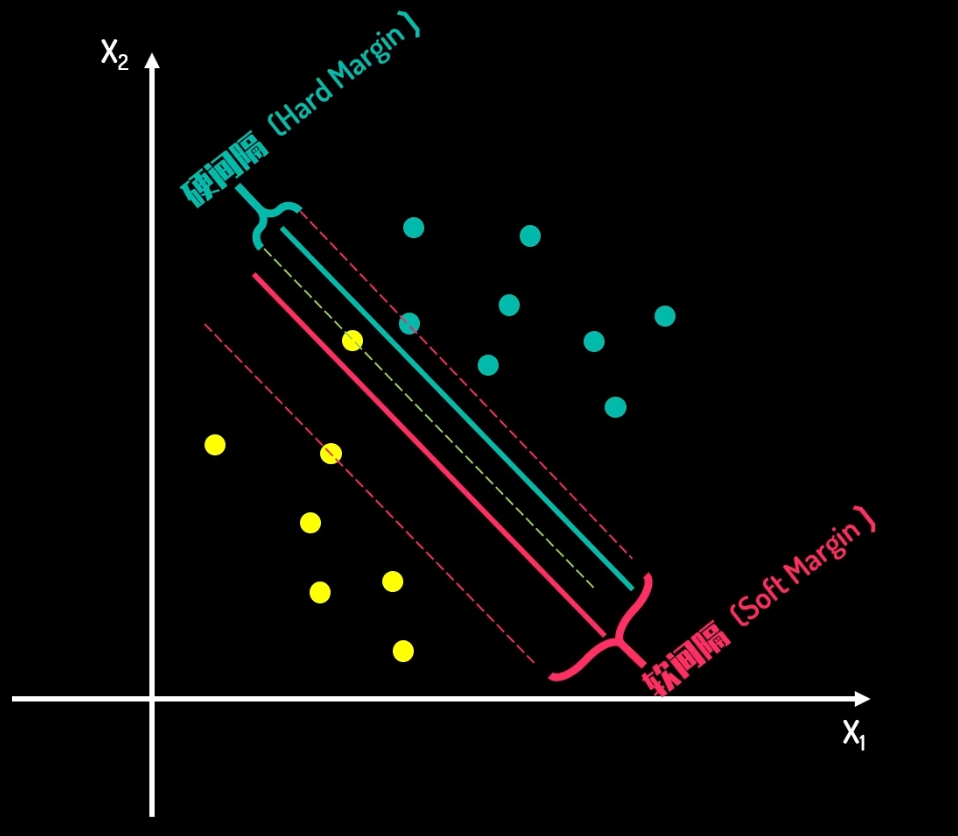
具体定义如下:
软间隔(Soft Margin)是指在支持向量机(SVM)中,对于一些非线性可分或受到噪声干扰的数据集,允许在寻找决策边界时有一些样本被误分类或距离决策边界的间隔不满足硬间隔的条件。软间隔 SVM 的目标是在最大化间隔的同时,允许一些样本违反间隔的要求,以提高模型的鲁棒性。
软间隔的主要思想是在寻找决策边界时,允许一些样本出现在决策边界的错误一侧或距离边界较近,以更好地适应现实中可能存在的噪声或异常点。这使得软间隔 SVM 在处理线性不可分的数据或受到噪声干扰的情况下更具有鲁棒性。
优化目标
代价函数
从逻辑回归开始,通过一点一点展示,得到软间隔中的代价函数$cost$
首先,逻辑回归的图像和$sigmoid$函数如下图所示:
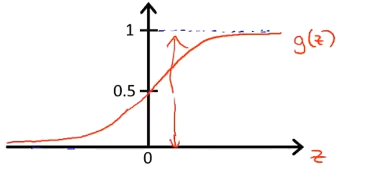
$y=1$的情况下,我们希望预测值$h_\theta(x)\approx 1$,此时$\theta^Tx\gg0$
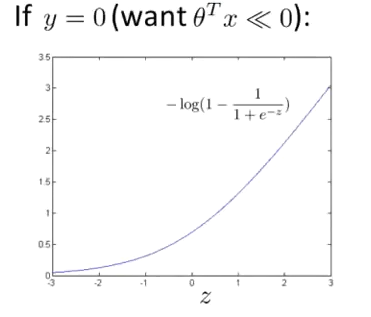
$y=0$的情况下,我们希望预测值$h_\theta(x)\approx 0$,此时$\theta^Tx\ll0$
进一步观察逻辑回归的代价函数:
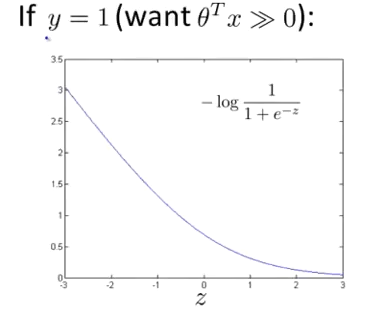
$y=1$时,$log {\frac{1}{1+e^{-\theta^Tx}}}$图像如下:
 |
 |
|---|---|
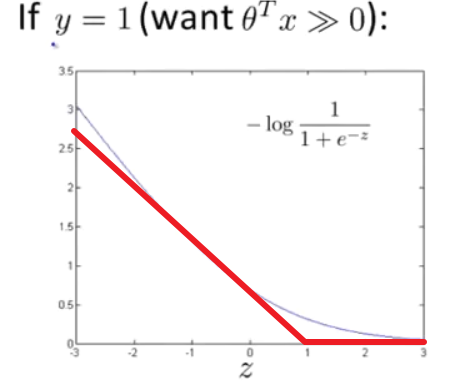
可以观察到,当$\theta^Tx>1$时,代价就已经很小了,在SVM中,我们把这条曲线近似为两条直线取$\theta^Tx=1$的点,将右边的所有值都看做是1
这里我们直接代入软间隔去直观的理解一下为什么要分成两段
当$\theta^Tx>1$时,如图所示:
此时数据相当于都在下面虚线以下,所以代价直接看做是0,对决策边界根本没有影响
当$\theta^Tx<1$时,说明数据点突破了决策边界,在不断的远离负超平面,所以代价越来越大
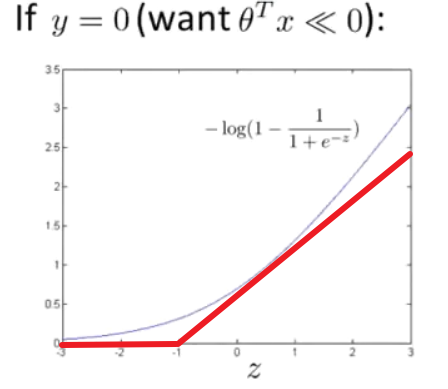
$y=0$时,代价函数$cost$图像如下:
 |
 |
|---|---|
可以观察到,当$\theta^Tx<-1$时,代价就已经很小了,在SVM中,我们把这条曲线近似为两条直线,取$\theta^Tx=-1$的点,将左边的所有值都看做是-1
联系之前提到的软间隔,显然当$\theta^Tx<-1$或者$\theta^Tx>1$的时候,数据点离决策边界较远,对决策边界的影响较弱,通过这样的设计,SVM 在优化过程中更加关注对那些接近决策边界的支持向量,即那些对于分类决策起到关键作用的样本。
这也是为什么在代价函数中使用两段线段的原因,以强调对于分类决策边界附近的支持向量的敏感性。这有助于建立一个在最大化分类间隔的同时,对分类错误的敏感度更强的分类器。
接下来简化代价函数:
用$cost$替换掉刚才的曲线,除去$1/m$这一项,当然,这仅仅是由于人们使用支持向量机时,对比于逻辑回归而言,不同的习惯所致,正则化系数也能简化,只保留$\frac{1}{2}$,去掉$m$和$\lambda$
在支持向量机(SVM)中,使用参数 C 来代替逻辑回归中正则化参数$\lambda$类似的作用。它控制了在训练数据的拟合与模型正则化项之间的权衡。
简化后公式如下:
C的作用和$\lambda$的正好相反,C越大,即代表的是$\lambda$越小,更容易过拟合,而C越小,说明容易欠拟合
核函数
SVM最广泛的应用的分类问题,而某些数据在低维度下很难进行分类,遇到这种情况时,需要考虑对数据进行升维,从而使数据易于分类
 |
 |
|---|---|
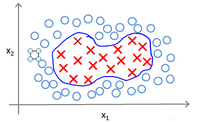
但是数据升维转换需要明确的维度转换函数,以及更多的存储要求,会大大增加程序的负担,为了避免将数据升维,可以直接使用核函数进行运算
核函数(Kernel Function)是支持向量机(SVM)中的一个关键概念。在 SVM 中,核函数用于将输入特征映射到高维空间,从而使得原始特征空间中的非线性问题能够在高维空间中变得线性可分。
核函数的主要作用是通过计算两个样本在高维空间中的相似性(内积)来替代在原始特征空间中的显式计算。这使得我们可以在高维空间中进行计算,而无需显式地知道或计算高维空间中的特征向量。核函数在 SVM 中的使用使得模型更加灵活,可以处理非线性的决策边界
常见的核函数有:
- 线性核函数(Linear Kernel): $K(x, y) = x^Ty$,对应于原始特征空间。
- 多项式核函数(Polynomial Kernel): $K(x, y) = (x^Ty + c)^d$,引入了多项式的高阶项。
- 高斯径向基函数核(Gaussian Radial Basis Function Kernel,RBF): $(K(x, y) = \exp\left(-\frac{|x-y|^2}{2\sigma^2}\right))$,引入了高斯分布的概念。
- Sigmoid核函数(Sigmoid Kernel): $K(x, y) = \tanh(\alpha x^Ty + c)$,模拟神经网络的激活函数。
核函数的选择通常取决于数据的性质和问题的要求。正确选择核函数可以显著提高 SVM 模型的性能。
这里介绍一下高斯核函数:
高斯径向基函数核(Gaussian Radial Basis Function Kernel,RBF Kernel)是支持向量机中常用的核函数之一。它的表达式如下:
其中:
- $( K(x, y) )$ 是样本 ( $x$ ) 和 ( $y$ ) 之间的内积,表示它们在高维空间中的相似性。
- $( |x-y| )$ 表示样本 ( $x$ ) 和 ( $y$ ) 之间的欧几里德距离。
- $(\sigma)$ 是控制高斯分布宽度的参数。
高斯径向基函数核的主要思想是将样本映射到一个无穷维的高维空间,并通过高斯分布来衡量它们之间的相似性。在这个高维空间中,样本之间的内积可以被计算,而不需要显式计算高维空间中的特征向量。这使得 SVM 在处理非线性问题时更为灵活。
关键点解释:
- 相似性度量: 如果两个样本 ( x ) 和 ( y ) 在原始特征空间中相似,它们在高维空间中的内积将更接近1,表现为高斯核函数的值更接近1,反之亦然。
- 参数 ( $\sigma$ ): 参数 ( $\sigma$ ) 控制了高斯分布的宽度。较小的 ( $\sigma$ ) 使得高斯分布更加尖锐,更强调相邻样本之间的相似性;较大的 ( $\sigma$ ) 使得高斯分布更加平滑,更强调整体样本之间的相似性。
- 非线性决策边界: 高斯径向基函数核允许 SVM 学习复杂的非线性决策边界,因为它可以通过内积的方式在高维空间中捕捉非线性关系。
接下来将说明如何具体的使用核函数来输入特征映射到高维空间中去
回顾我们之前讨论过可以使用高级数的多项式模型来解决无法用直线进行分隔的分类问题:
为了获得上图所示的判定边界,我们的模型可能是$(\theta_0 + \theta_1 x_1 + \theta_2 x_2 + \theta_3 x_1 x_2 + \theta_4 x_1^2 + \theta_5 x_2^2 + \ldots) $的形式。
我们可以用一系列的新的特征$f$来替换模型中的每一项。例如令:
$\ f_1 = x_1, f_2 = x_2, f_3 = x_1 x_2, f_4 = x_1^2,f_5 = x_2^2, \ldots $得到$h_θ(x)={\theta _{1}}f_1+{\theta _2}f_2+…+{\theta_n}f_n$。
然而,除了对原有的特征进行组合以外,有的方法来构造$f_1,f_2,f_3$,我们可以利用核函数来计算出新的特征。
给定一个训练样本$x$,我们利用$x$的各个特征与我们预先选定的地标(landmarks)$l^{(1)},l^{(2)},l^{(3)}$的近似程度来选取新的特征$f_1,f_2,f_3$。
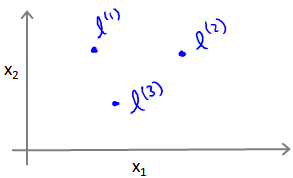
这里的地标通常指的是一组特定的点,这些点被选择用于构建新的特征,从而将数据映射到更高维度的空间。这个过程有时称为特征映射。
具体来说,在使用核函数的情况下,我们选择一组地标,通常是从训练集中选择的数据点,作为新特征的基础。对于每个训练样本,我们计算它与地标之间的相似性,然后利用这些相似性值构建新的特征。这样,原始的特征空间被映射到一个更高维度的空间,使得在高维空间中的数据更容易被线性分离。
例如:$ f_1 = \text{similarity}(x,l^{(1)}) = e\left(-\frac{||x-l^{(1)}||^2}{2 \sigma^2}\right) $
其中:$ | x - l^{(1)} |^2 = \sum_{j=1}^n (x_j - l_j^{(1)})^2 $,为实例$x$中所有特征与地标$l^{(1)}$之间的距离的和。上例中的$similarity(x,l^{(1)})$就是核函数,具体而言,这里是一个高斯核函数(Gaussian Kernel)
如果一个训练样本$x$与地标$l$之间的距离近似于0,则新特征 $f$近似于$e^{-0}=1$,如果训练样本$x$与地标$l$之间距离较远,则$f$近似于$e^{-(一个较大的数)}=0$。
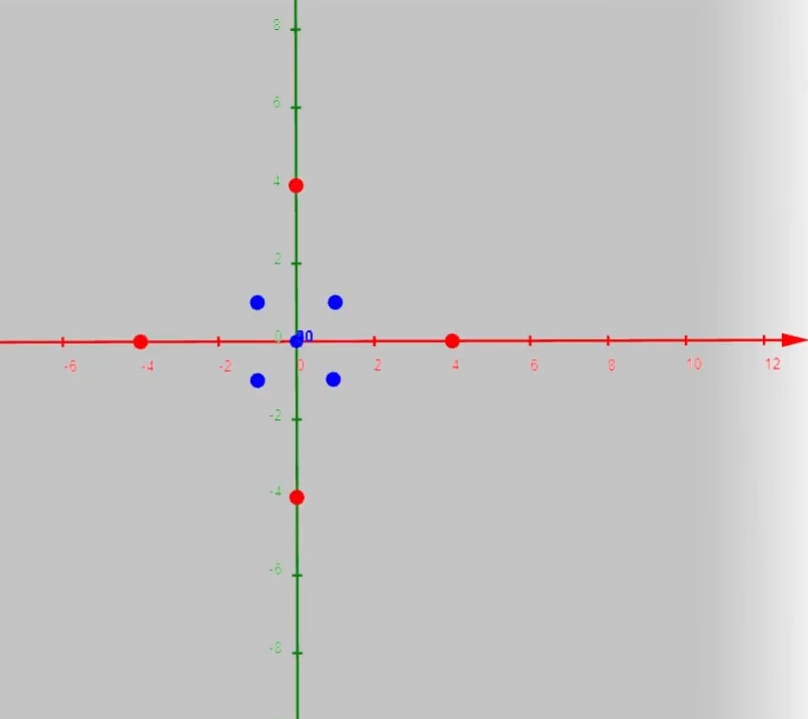
在下图中,当样本处于洋红色的点位置处,因为其离$l^{(1)}$更近,但是离$l^{(2)}$和$l^{(3)}$较远,因此$f_1$接近1,而$f_2$,$f_3$接近0。因此$h_θ(x)=θ_0+θ_1f_1+θ_2f_2+θ_1f_3>0$,因此预测$y=1$。同理可以求出,对于离$l^{(2)}$较近的绿色点,也预测$y=1$,但是对于蓝绿色的点,因为其离三个地标都较远,预测$y=0$。
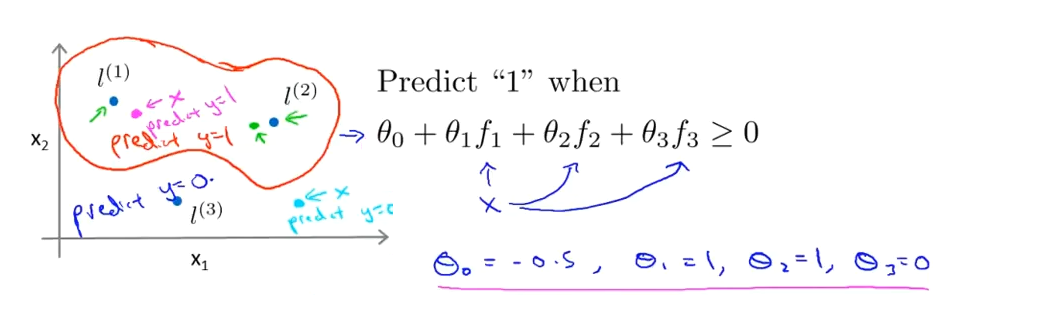
这样,图中红色的封闭曲线所表示的范围,便是我们依据一个单一的训练样本和我们选取的地标所得出的判定边界,在预测时,我们采用的特征不是训练样本本身的特征,而是通过核函数计算出的新特征$f_1,f_2,f_3$
那么该如何选取地标?
通常是根据训练集的数量选择地标的数量,即如果训练集中有$m$个样本,则我们选取$m$个地标,并且令:$l^{(1)}=x^{(1)},l^{(2)}=x^{(2)},…..,l^{(m)}=x^{(m)}$。这样做的好处在于:现在我们得到的新特征是建立在原有特征与训练集中所有其他特征之间距离的基础之上的,即:
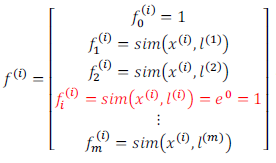
下面我们将核函数运用到支持向量机中,修改我们的支持向量机假设为:
- 给定$x$,计算新特征$f$,当$θ^Tf>=0$ 时,预测 $y=1$,否则反之。
相应地修改代价函数为:$\sum{_{j=1}^{n=m}}\theta _j^2=\theta^T\theta $,
在具体实施过程中,我们还需要对最后的正则化项进行些微调整,在计算$\sum{_{j=1}^{n=m}}\theta _j^2={\theta^T}\theta $时,我们用$θ^TMθ$代替$θ^Tθ$,其中$M$是根据我们选择的核函数而不同的一个矩阵。这样做的原因是为了简化计算。
理论上讲,我们也可以在逻辑回归中使用核函数,但是上面使用 $M$来简化计算的方法不适用与逻辑回归,因此计算将非常耗费时间。
在此,我们不介绍最小化支持向量机的代价函数的方法,你可以使用现有的软件包(如liblinear,libsvm等)。在使用这些软件包最小化我们的代价函数之前,我们通常需要编写核函数,并且如果我们使用高斯核函数,那么在使用之前进行特征缩放是非常必要的。
另外,支持向量机也可以不使用核函数,不使用核函数又称为线性核函数(linear kernel),当我们不采用非常复杂的函数,或者我们的训练集特征非常多而样本非常少的时候,可以采用这种不带核函数的支持向量机
下面是支持向量机的两个参数$C$和$\sigma$的影响:
$C=1/\lambda$
$C$ 较大时,相当于$\lambda$较小,可能会导致过拟合,高方差;
$C$ 较小时,相当于$\lambda$较大,可能会导致低拟合,高偏差;
高斯核函数 $e\left(-\frac{||x-l^{(1)}||^2}{2 \sigma^2}\right)$
$\sigma$较大时,可能会导致低方差,高偏差;
$\sigma$较小时,可能会导致低偏差,高方差。
多类分类问题
假设我们利用之前介绍的一对多方法来解决一个多类分类问题。如果一共有$k$个类,则我们需要$k$个模型,以及$k$个参数向量$$。我们同样也可以训练$k$个支持向量机来解决多类分类问题。但是大多数支持向量机软件包都有内置的多类分类功能,我们只要直接使用即可。
尽管你不去写你自己的SVM的优化软件,但是你也需要做几件事:
1、是提出参数$C$的选择。我们在之前的视频中讨论过误差/方差在这方面的性质。
2、你也需要选择内核参数或你想要使用的相似函数,其中一个选择是:我们选择不需要任何内核参数,没有内核参数的理念,也叫线性核函数。因此,如果有人说他使用了线性核的SVM(支持向量机),这就意味这他使用了不带有核函数的SVM(支持向量机)
总结
| 场景 | 逻辑回归 | 支持向量机(SVM) | 神经网络 |
|---|---|---|---|
| 特征数 (n) 较大,(m) 较小 | 适用,训练速度相对较快 | 不适用 | 适用,训练速度可能较慢 |
| (n) 较小,(m) 在 10-10000 之间 | 适用,尤其是不带核函数的 SVM | 适用 | 适用,但可能有更快的选择 |
| (n) 较小,(m) 大于50000 | 适用,训练速度相对较快 | 不适用 | 适用,但训练可能较慢 |
说明:
- 对于小规模数据集,特别是当特征数量较大时,逻辑回归或不带核函数的 SVM 是常用的选择,因为它们的训练速度相对较快。
- 当面对中等规模数据集,特别是特征数量较小,可以尝试使用高斯核函数的 SVM。
- 对于复杂的非线性函数拟合,或者存在大量数据和特征的情况,神经网络可能是一个有效的选择,但训练时间可能较长。
- 对于大规模数据集,支持向量机通常是比较高效的选择,尤其是在使用不同的核函数时。
7777

