
1.机器学习绪论
机器学习绪论
监督学习
监督学习是一种机器学习的方法,它的目的是训练一个模型,使其能够根据输入数据预测输出数据。监督学习需要使用一些已经标注了输出数据的输入数据作为训练集,例如图片和对应的标签,或者文本和对应的类别。
通过学习训练集中的数据,监督学习模型可以找到输入和输出之间的关系,从而对新的输入数据进行分类或回归。监督学习有很多应用场景,例如图像识别、垃圾邮件过滤、情感分析等。
监督学习可以分为两种类型:分类和回归
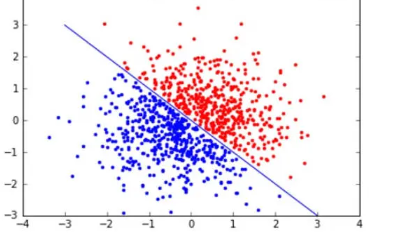
分类问题
分类是指将输入数据分配到有限个离散的类别中,例如判断一封邮件是垃圾邮件还是正常邮件。
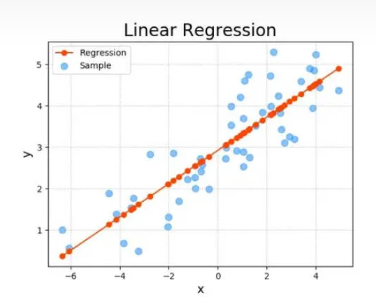
回归问题
回归是指将输入数据映射到一个连续的数值上,例如预测房价或股票价格。
监督学习的模型有很多种,例如神经网络、支持向量机、决策树、逻辑回归等。不同的模型有不同的优缺点和适用场景,选择合适的模型需要考虑数据的特征、规模、分布等因素。
无监督学习
无监督学习是一种机器学习的方法,它的目的是在没有标签或目标的情况下,从数据中发现隐藏的结构或模式。
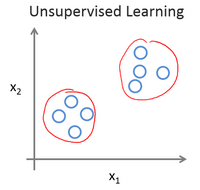
无监督学习有很多应用场景,例如数据聚类、降维、异常检测、推荐系统等
聚类是一种机器学习的方法,它可以把相似的数据分成不同的组,每个组叫做一个簇。聚类的目的是让同一个簇里的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。聚类可以用来分析数据的结构、模式、特征等。

